
On-Policy Control with Approximation
앞서 On-policy evaluation을 approximate 했다면,

앞 시간을 잘 이해했다면, 이번 포스팅은 state-value대신에 action-value만 대입한다는 느낌으로 학습하면 쉽게 이해할 수 있을 것이라 예상한다. 왜냐하면 이번에도 마찬가지로 action-value function의 parametric approximation에 대해서 알아볼 예정이기 때문이다.
Episodic Semi-gradient Control
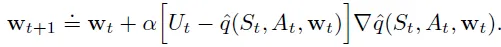
![]()
마찬가지로 Ut의 자리에는 estimate가 위치할 수 있고, 위와 같이 one-step sarsa의 estimate를 대입하면 episodic semi-gradient one-step sarsa라 부른다.
다음 step은 control problem을 풀어야 하는데, action-value와 더불어서 policy improvement와 action-selection을 진행하게 된다.
다만, 너무 큰 continuous action space에 대해서는 여전히 연구중인 분야이고, 적절한 discrete action space의 경우는 greedy 나 ε-greedy를 적용하면 풀 수 있다.



- On-Policy prediction : tile-coding function approximation
- On-Policy control : one-step semi-gradient Sarsa & ε-greedy
n-step Semi-gradient Sarsa
마찬가지로 n-step version의 episodic semi Sarsa를 적용하기 위해 아래 n-step return 을 update target으로 활용할 수 있다.



Average Reward
continuous 문제에 reward를 도입하는 것은 만만치 않다. 물론 당장의 얻는 reward는 사용자의 정의에 따라 얻을 수 있지만, 통상 continuous 문제는 terminal state가 없거나 episode가 매우 길기 때문에 우리에게 필요한 것은 역시 '근사화'하는 것이다.
일전에 Markov decision problem을 정의하면서 episodic discounted reward을 사용한 것 처럼,
continuous problem에서는 average reward를 사용한다. 여기서는 MDP처럼 discounting을 고려하지 않는다. 즉, delayed rewards에 대해 immediate reward와 같은 비중으로 고려한다.
average reward setting에서는 policy π의 quality는 아래와 같이 average rate of reward r(π)로 정의한다.

위 식의 dπ(s)는 state distribution으로 policy π에 따라 action이 선택되는 경우, 분포가 변하지 않음으로 아래와 같의 정의될 수 있다. (책에는 μπ(s)로 표기하고 있다.)

그리고 average reward setting에서 reward는 reward와 average reward의 차(difference)를 기준으로 아래와 같이 정의된다.

※ 단순히 γ를 없애고, 모든 reward를 difference로 대체한다.



 는 average reward
는 average reward ") 평균값의 예측치이다.
평균값의 예측치이다. 이와 같은 정의를 사용하면 대부분의 algorithm이나 이론적인 결과물들을 average reward setting으로 전환하여 사용가능하다.
예를 들면, average reward version의 semi-gradient Sarsa는 아래와 같이 정의 될 수 있다.
※ update of parameter for average rewards semi-gradient Sarsa is


![[빅분기] PART4. 빅데이터 결과 해석 - 분석결과 해석 및 활용 - 분석결과 활용 (출제빈도 : 하)](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEj2tCMzQ5D2rhqkDfbphh9LKohFnYl3Df8LahM8gskD0BNHA5jX1MLhVIuG78S5IdyrrQrB60ygONq5FvYBLzrUnJrOhKpTfTFzZP0TFS_lZDipN44DhIq8FfFfnieRwTSzDCXvKacFQWvlcETOaoxXS0KNSFdN3apRHi5ReqUer7jCvbIFp2tj8Gmqci3S/w680/%EB%B9%85%EB%8D%B0%EC%9D%B4%ED%84%B0%20%EA%B5%AC%EC%B6%95%EB%B0%A9%EB%B2%95%EB%A1%A0%20%EB%B9%84%EA%B5%90.png)
0 댓글