
Multi-view Geometry

영상처리의 중요한 개념 중 하나는 바로 depth이다. 즉, 영상 내 원근감을 나타내는 것이다.
사실 위 그림과 같은 느낌의 영상은 큰 렌즈와 함께 조리개를 조절해서 초점을 맞춰야하는데, 이 기능을 영상처리로 표현할 수 있다. 예를 들어 위 이미지는 foreground 를 더 선명하고 background를 blur처리 한 것을 보여준다.

사실 이런 기법은 일반적인 카메라가 아니라 depth를 함께 측정해야 가능했었다.


하지만 1개 영상을 통해서 원근감을 측정하기 위한 기술들이 발전하기 시작했다. 예를 들면 vanishing point를 찾거나, 유사한 object의 size들로 depth를 유추하기 시작한 것이다.
Camera model
이 기술에 대해 알아보기전에 3차원의 현실이 어떻게 영상에 맺히는지를 알아보자.

이 때 2가지 projection을 정의할 수 있는데, Perspective project이 원근감을 잘 표현하는 projection이라고 할 수 있다. 이렇게 Perspective project를 가능케 하는 것이 바로 stereo vision이다.
하지만 pinhole 원리에 기반한 카메라는 model을 활용해 1개 카메라로 perspective project을 구현했었고,

이런 원리를 구현한 모델로는 위와 같이 다양한 모델들이 있다.
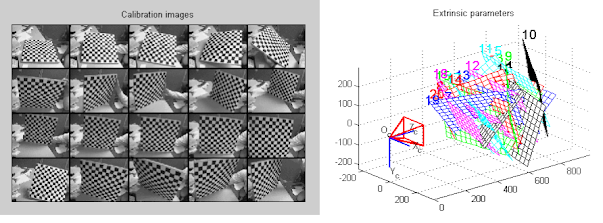
다만, 임의로 만든 두 stereo vision의 파라미터 (ex. 영상간 거리, 회전량 등)를 정확히 파악하는 것이 중요한데 이 과정을 camera calibration이라고 한다.
camera calibration을 위와 위 그림과 같은 격자무늬를 촬영하게 되고, 이 과정에서

렌즈의 상태를 점검하거나 distortion 양을 측정해서 파라미터를 수정하곤 한다.

하지만 카메라가 1개일 때 pinhole과 동일한 선상에 object가 있으면 현재 맺힌 object가 어떤 object인지 알 수 없다는 문제가 발생한다.


위 그림은 2개 stereo vision을 활용해 depth map을 유추한 결과를 보여준다. (어두운 색은 depth가 깊은 것)
그럼 stereo vision 기술의 원리에 대해 좀 더 알아보자.

일단 해결해야 할 첫번째 문제는 촬영된 두 영상을 reflection 시키는 것이다.

즉, 왼쪽 영상에서 object에 해당하는 patch의 위치와 오른쪽 영상에서 동일한 object에 해당하는 patch를 sync시켜줘야 하는 것이며, 그 기능을 컴퓨터로 구현하기 위해서는 위와 같이 두 이미지를 reflection 시켜준 후 matching단계로 넘어가야 한다.

이렇게 reflection 된 이미지가 2장 있으면 같은 수평선상에서 matching cost를 계산해서 동일한 object끼리 짝을 지어줄 수 있다. stereo vision을 위한 pipeline을 정리하면 아래와 같다.
- Calibrate camera
- Rectify images
- Compute disparity
- Estimate depth
※ matching cost function에는 SSD나 correlation을 비교하는 방법 등이 있다.
다만 이 방법에는 이미지에 유사한 패턴이 반복될 때 matching cost가 잘 계산되지 않는점, 두 카메라가 매우 가까워서 noise에 취약한 점 등의 risk를 해결할 필요가 있다. 그리고 비교대상인 patch의 크기(window size)를 잘 정하는 것도 성능에 큰 영향을 미친다.
그래서 더 나은 stereo matching 문제를 해결하기 위해 better matching cost function, adaptive window size 등의 연구가 활발히 진행 되었다.
최근에는 stereo vision에도 DNN이 적용되고 있고, 학습을 위한 dataset도 상당히 공유된 상태이다.
※ https://vision.middlebury.edu/stereo/
※ https://cityspaces-dataset.com/
※ https://cs.nyu.edu/~silberman/datasets/nyu_depth_v2.html

위 그림은 stereo vision을 위한 네트워크인 GC-Net을 보여준다.
※ Kendall et al., End-to-End Learning of Geometry and Context for Deep Stereo Regression, ICCV 2017
- 입력층에 2대의 카메라로부터 촬영된 영상이 입력되고, (feature extraction)
- 두 네트워크의 출력의 matching cost를 계산하는 cost volume construction
- 그리고 이 cost volume을 smoothing시키고 (cost aggregation)
- Decovolution연산을 통해 depth를 표현하는 이미지를 생성시킨다. (disparity computation)

여기서 더 발전해서 1개 이미지에 DNN을 통해 depth estimation하는 연구도 최근 진행됐다. 이 분야에서는 단순히 matching만 잘 하는 것이 아니라 이미지를 넓게 보는 시야를 구현해야 한다.

※ Eigen et al., Depth map prediction from a single image using a multi-scale deep network, NIPS 2014
이 논문에서는 대략적으로 영상을 파악하는 네트워크와 그 결과를 이용해 구체적인 depth를 유추해내는 네트워크를 제안하였다.

또 다른 논문에서는 single image를 학습한 CNN이 2개의 stereo 영상을 출력하는 방법도 고안되었다.
※ Godard et al., Unsupervised Monocular Depth Estimation with Left-Right Consistency, CVPR 2017
![[빅분기] PART4. 빅데이터 결과 해석 - 분석결과 해석 및 활용 - 분석결과 활용 (출제빈도 : 하)](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEj2tCMzQ5D2rhqkDfbphh9LKohFnYl3Df8LahM8gskD0BNHA5jX1MLhVIuG78S5IdyrrQrB60ygONq5FvYBLzrUnJrOhKpTfTFzZP0TFS_lZDipN44DhIq8FfFfnieRwTSzDCXvKacFQWvlcETOaoxXS0KNSFdN3apRHi5ReqUer7jCvbIFp2tj8Gmqci3S/w680/%EB%B9%85%EB%8D%B0%EC%9D%B4%ED%84%B0%20%EA%B5%AC%EC%B6%95%EB%B0%A9%EB%B2%95%EB%A1%A0%20%EB%B9%84%EA%B5%90.png)
{kind=link}
0 댓글