
Morphology(형태론)
& Morphological Parsing
NLP를 위해 문장의 형태를 파악하는 것은 매우 중요하고 기본이라 할 수 있다. 문장의 형태(morphology)를 구성하는 기본요소에 대해 알아보도록 하자.
Word form & Lemma
- Form(=word) : 단어를 의미에 따라 1개 form으로 묶은 것
ex. run, runs, ran은 같은 form이다.
- Lemma : Run, RUN, runs 를 기본형인 run으로 인식하는 것.
Word Class : 형용사, 관용사 등 단어의 class를 파악하는 것
Morphemes(형태소) : 의미를 가지는 작은 언어 단위 (ex. builder → build + er}
- 형태소는 Root(어근)와 Affix(접사)로 나눠진다. 위 예제에서는 build가 root, -er이 affix이다.
- Affix는 Derivational(파생접사 : 새로운 단어를 만들어내는 접사. ex. '짓'밟다)
/ Inflectional(굴절접사 : 기능을 추가하는 접사. ex. 짓밟'으니')로 구분됨.
Stem(어간) : 단어에서 굴절접사를 떼고 남은 부분 ('ex. '짓밟'다)
Computational Morphology : Task
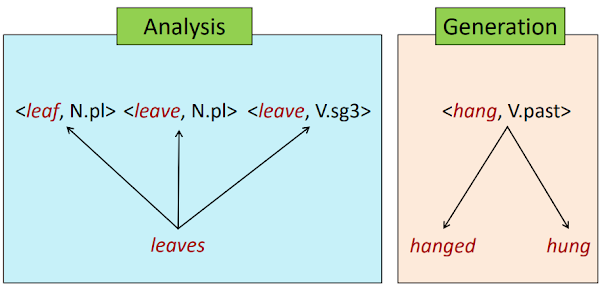
형태소 분석(analysis)은 surface word form이 입력됐을 때 lemma와 morphological features를 찾는 것이다.
※ 반대로 형태소 생성(generation)은 lemma와 morphological properties가 주어졌을 때 surface word form을 생성하는 것이다.
그럼 형태소 분석 단계를 알아보도록 하자.

- Segmentation (Tokenization) : word를 morphemes로 잘게 자른다.
(ex. leaves → leave + s, 감기는 → 감기 + 는 or 감 + 기 + 는)
- Morpheme Sequence Labeling : word의 sequence를 지정하는 것 (partial order)
(ex. leave + s 의 s는 leave뒤에 붙는다.)
- Lemmatization : 단어의 기본형을 찾는 것
형태소 생성단계는 보다 간단하다. (그래서 언어 이해보다 생성이 더 쉽다.)

Computational Morphology : Approaches
morphology를 계산하기 위한 방법은 크게 3가지로 나뉠 수 있다.

- Simple approach : 모든 단어의 의미와 sequence order (full form)를사전으로 지정하는 것 (복잡한 언어ex. 한글 에서는 거의 불가능) 매우 빠르고 정확하지만 모든 form을 파악하는 것이 불가능에 가깝다. 물론 사전이 클수록 메모리 사용량도 기하급수적으로 올라간다.
- Linguistic approach : rule과 dictionary를 활용해 형태소를 분석한다.

자연어 처리에는 적용이 어렵지만 정보검색에는 유용하게 쓰일 수 있다.
(U. Cambridge Porter Stemmer : http://tartarus.org/~martin/PorterStemmer/)
2) Rules + Dictionary : rule과 사전을 모두 사용하는 방법이다.
관련 원리를 설명하기엔 너무 전문적으로 파고 들기 때문에 포스팅에선 생략한다.
관련 원리를 설명하기엔 너무 전문적으로 파고 들기 때문에 포스팅에선 생략한다.
(NLTK Demos : http://text-processing.com/demo/)
- ML approach : training기반의 알고리즘을 활용. 기존의 resource(dictionary)가 없는 경우 유용하다.
![[빅분기] PART4. 빅데이터 결과 해석 - 분석결과 해석 및 활용 - 분석결과 활용 (출제빈도 : 하)](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEj2tCMzQ5D2rhqkDfbphh9LKohFnYl3Df8LahM8gskD0BNHA5jX1MLhVIuG78S5IdyrrQrB60ygONq5FvYBLzrUnJrOhKpTfTFzZP0TFS_lZDipN44DhIq8FfFfnieRwTSzDCXvKacFQWvlcETOaoxXS0KNSFdN3apRHi5ReqUer7jCvbIFp2tj8Gmqci3S/w680/%EB%B9%85%EB%8D%B0%EC%9D%B4%ED%84%B0%20%EA%B5%AC%EC%B6%95%EB%B0%A9%EB%B2%95%EB%A1%A0%20%EB%B9%84%EA%B5%90.png)
{kind=link}
0 댓글