
Image alignment

image alignment는 여러장의 영상을 정렬시키는 것이다. 이 기능은 위와 같이 파노라마 사진을 만들기도하고, 동영상의 떨림을 보정할 수도 있다.
Feature Detecting

image alignment는 결국 translation이 발생한 두 영상을 정렬시키는 것이고, 어떤 translation이 발생했는지 파악하는 것이 중요하다.
Direct alignment는 두 영상이 얼마나 많이 겹치는지로 translation matrix를 판단하는 방법이다.
※ Ex. Sum of Squared Difference(SSD), Sum of Absolute Difference (SAD), Normalized Cross Correlation(NCC), edge matching, etc...

하지만 이 방법은 translation matrix의 전체 파라미터를 찾기에는 시간이 너무 많이 걸린다.

그래서 두 영상의 차이를 최소화하는 파라미터를 찾는 optimization문제로 전환한 방법인 Lucas-Kanade 알고리즘이 고안되기도 하였다.

그럼 위 그림처럼 feature를 몇개 지정한 다음, 두 영상에서 그 feature가 얼마나 translation되었는지를 찾을 수 있게 된다.
이때 선택된 feature는 경기장의 모서리처럼 well localized하고, contrast가 높아서 well matched된 feature point를 찾는 것이 중요하다.
(물론 OpenCV와 같은 open source library에 feature point detection 알고리즘이 모두 내장되어 있다.)

feature point detection방법에도 여러가지 방법이 있는데, 가장 간단한 방법으로는 Harris corner detector가 있다. 이 알고리즘은 "일반적으로 object의 corner가 좋은 feature이다." 라는 가정을 직설적으로 구현하는 것이다. 왜냐하면 corner야 말로 상하좌우 어디로 이동하든 픽셀의 변화가 일어나는 훌륭한 feature이기 때문이다.

위 식은 픽셀의 이동량을 측정하는 식이며,

역시나 corner이미지의 translation을 모든 방향에서 파악할 수 있게 해 주는 것을 볼 수 있다.
(mathematical 증명 혹은 방법은 여기서 자세하게 다루지 않는다. 최소한의 원리는 이해하고 open source를 사용하자.)

이 원리를 일반화 하면 corner response value R을 통해 thresholding으로 이미지 내 corner를 어느정도 detect할 수 있다.

하지만 Harris corner detector의 문제점은 scale에 invariant하지 않다는 것이다. 즉, 멀리서 봤을땐 코너인데 가까이에서 보면 edge로 판단할 수도 있다는 것이다.

이런 문제를 해결하기 위해 픽셀 주변영역으로 window를 확장해서 corner를 detecting할 수 있다.
지금까지 가장 간단한 feature detector인 Harris corner detector의 원리에 대해 간단히 살펴봤는데, 지금은 SIFT, SURF, FAST, ORB와 같은 상당히 발전된 알고리즘이 많이 연구되었다.
Feature matching

feature point를 정의했으면 이제 translation 된 영상의 feature와 matching을 시켜줘야 한다.
가장 간단한 방법은 feature 픽셀 주변의 patch를 서로 비교해보는 것이다. 하지만 빛의 밝기, 스케일 등에 따라 안정적으로 matching시킬 수 있는 방법은 아니다.
결국 feature를 잘 표현하는 어떤 방법이 필요한데, 이 개념이 바로 feature descriptor이다.
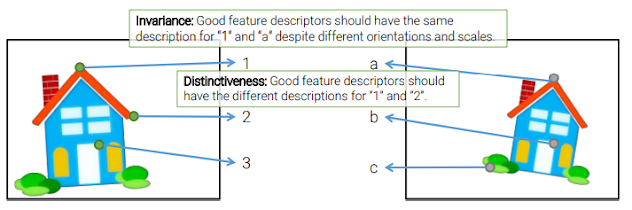
이 때 feature descriptor는 밝기/스케일/회전 등의 변화에 robust해야하고, feature들을 잘 구분할 수 있는 특징이 기술되어야 한다.

그래서 간단한 방법으로는, 위와 같이 local orientation을 찾아서 두 개 patch를 같은 feature로 인식시키는 방법이 있다.
feature detector도 SHIFT, SURF, BRIEF, BRISK, FREAK 등 다양한 발전된 알고리즘들이 있고 공개 되어 있다. (SHIFT와 SURF를 가장 많이 사용한다. 참고로 SURF는 licence free인지 체크해봐야한다.)

실제로 소개한 알고리즘을 돌려보면 위와 같이 feature matching이 이루어진 결과를 얻을 수 있다. 그런데 중간중간 잘못 matching된 outlier들이 눈에 보인다. 그래서 outlier를 탐지하는 알고리즘도 매우 중요하다고 할 수 있다.
그 중 RANSAC(RANdome SAmple Consensus)은 여러번의 random sampling을 통해 데이터의 대표값을 찾는 알고리즘인데, 영상처리에서도 다방면에서 활용되는 알고리즘이다.

- RANSAC은 matching된 결과들 중 random하게 하나를 뽑고 translation 파라미터를 찾는다.

- 그리고 그 파라미터가 전체 match들 중 몇개가 inlier인지 counting한다.
- 최종적으로 inlier가 가장 많은 translation 파라미터의 평균을 대표 파라미터로 결정한다.
![[빅분기] PART4. 빅데이터 결과 해석 - 분석결과 해석 및 활용 - 분석결과 활용 (출제빈도 : 하)](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEj2tCMzQ5D2rhqkDfbphh9LKohFnYl3Df8LahM8gskD0BNHA5jX1MLhVIuG78S5IdyrrQrB60ygONq5FvYBLzrUnJrOhKpTfTFzZP0TFS_lZDipN44DhIq8FfFfnieRwTSzDCXvKacFQWvlcETOaoxXS0KNSFdN3apRHi5ReqUer7jCvbIFp2tj8Gmqci3S/w680/%EB%B9%85%EB%8D%B0%EC%9D%B4%ED%84%B0%20%EA%B5%AC%EC%B6%95%EB%B0%A9%EB%B2%95%EB%A1%A0%20%EB%B9%84%EA%B5%90.png)
{kind=link}
1 댓글
SHIFT -> SIFT
답글삭제