
Image Synthesis & Generative Adversarial Networks
Image Synthesis(합성)
Texture synthesis
이미지 합성에 대해 알아보기 전에, DNN 이전의 이미지 합성에 대해서 알아보도록 하자.

가장 간단한 이미지 합성은 Texture synthesis이다. Texture synthesis는 이미지 내 구멍을 메꾸거나, 가상의 환경을 채우거나, view 확장 등 다양하게 활용될 수 있다.

가장 간단한 방법은 화장실 타일 붙이듯 격자형태로 배열하는 tiling이 있는데 보다시피 좋은 방법은 아니다. 조금 더 나은 방법으로 random하게 덧붙이는 방법이 있긴한데 이 또한 좋은 품질을 기대하긴 어렵다.
그래서 예전에는 총 2가지 정도의 approach를 시도했다.
Approach 1: probabilistic modeling

첫 번째 방법은 input texture가 특정 distribution을 따른다고 가정하고, 그 distribution에서 sampling해서 합성하는 방법이다.
그런데 그 결과를 보면 실제로 분포의 추측이 가능한 단순한 패턴(좌)에서는 쓸만하지만, 그게 아니라면(중,우) 전혀 다른 패턴을 보여주곤 한다.
Approach 2: sample from the image
그래서 고안된 방법이 바로 원본 이미지 내에서 패턴을 sampling하는 방법이다.

위 그림은 P위치의 픽셀값을 결정하기 위해서 가장 비슷한 패턴을 여러개 찾은 뒤, 그 중 1개 패턴을 random하게 선택하는 과정을 보여준다.
Inpainting

Inpainting은 이미지에서 특정 부분을 지우고 주변과 잘 어우러지게 그 빈공간을 채우는 기술이다. 사실 이미지에 특정 영역을 지우는 것은 쉬운 일이기 때문에 inpainting은 hole을 주변 texture로 자연스럽게 채우는 것이라 할 수 있다.
채우는 방법 중 하나는 onion-peel fill이다. 이 방법은 hole의 외곽부분에서 안쪽으로 채우는 과정을 의미한다. 하지만 외곽부터 집중하다 보면 위 그림처럼 원하는 방향으로 채워지지 않을 수 있는데, 보다 더 자연스럽게 hole을 채울 수 있는 방법이 바로 gradient-sensitive order이다.
gradient-sensitive order는 hole에 해당하는 픽셀들 중 ① 주변 픽셀에 의해 둘러싸여있어 바로 결정이 가능한 픽셀, ② 강한 edge를 가지는 픽셀을 우선적으로 채워주는 과정이며, onion-peel fill에 비해 훨씬 효과적임을 위 그림에서 확인할 수 있다.
Texture transfer

Texture transfer는 object에 새로운 texture를 씌워주는 합성법이다. source texture에서 target image와 가장 유사한 patch를 가져와서 변형시켜준다.
Image analogies

Image analogies는 A, A'를 알고, B가 주어졌을 때 B'(synthesized image)를 구하는 것이다.
※ Hertzmann et at., "Image Analogies", SIGGRAPH 2001
위 기능의 구현을 위한 pseudo code를 보면 아래와 같다.
- A의 patch들과 B의 patch를 비교해서 가장 비슷한 patch의 쌍을 찾는다.
- A'의 patch를 B'에 복사해준다.




이렇게 간단한 원리로 Blurring, Edge filtering, Artist filtering, Colorization, Super-resolution 등 다양한 영역에 적용할 수 있다.
Patchmization
지금까지 synthesize 예제를 봤는데, 공통점은 이미지의 patch를 기반으로 목적을 달성하는 것이다. 그만큼 patch를 잘 정의하는 것은 매우 중요하다.
이런 patch기반의 방법은 성능은 만족스러운데, ①patch 안에 많은 정보를 담으로면 patch size가 커야하고, ② full 이미지에 대해 patch를 생성해 processing해야하기 때문에 매우 느리다는 단점이 있었다. 그리고 단점을 극복하기 위한 다양한 알고리즘이 제안되었다.
그 중 가장 파급력 있었던 논문은 Patch Match이다.

Patch Match는 사용자가 Patch를 수동으로 선택하면 그 이미지의 패턴을 자연스럽게 원본 이미지에 합성시키는 예제를 보여주는데, patch 기반임에도 불구하고 매우 빠른 속도를 보여준다. (예제 실행 동영상을 보면 더 신기하다.)
※ Barnes et al., PatchMatch: A Randomized Correspondence Algorithm for Structural Image Editing, SIGGRAPH 2009

Patch match알고리즘에서는 patch를 빠르게 검색할 수 있는 방법을 제안한다. 예를 들면 왼쪽 사진의 '손'과 가장 비슷한 patch를 오른쪽 사진에서 찾는 것이다. (Nearest Neighbor Field)
이 때 우리의 목표는 A의 patch인 p와 가장 비슷한 B의 patch인 q를 찾는 것이다.
가장 간단한 방법은 이미지 왼쪽위에서 오른쪽아래까지 조금씩 이동하며 가장 비슷한 patch를 찾는 것이다. 그럼 예상대로 무지하게 느리게 동작한다.
Patch match의 첫 번째 아이디어는 random offset이다.

일단 A이미지의 몇개의 patch를 random하게 B의 patch와 pair시키며 initialize시킨다.
그리고 두번째 아이디어는 spatial coherence이다.

예를 들면 A에서 p가 있었던 위치와 비슷한 곳에 B에서도 유사한 패턴이 있을 것이라 가정하는 것이다.

이 과정을 도식화 하면 위와 같다.
- (a) random initialization : 일단 random하게 pair를 이룬다.
- (b) propagation : 빨간 patch가 우연히 유사한 패턴을 갖는 patch를 찾았다. 그럼 파란색 patch의 pair도 그 주변에 있을 것이라 가정하고 update한다. (정보가 전파된다.)
- (c) search : 빨간 patch 주변을 확장해서 가장 비슷한 patch를 찾는다.
이 방법은 기존의 patch search 방법을 상당수준 가속화 시킬 수 있는 성과를 가져왔고, non-local means denoising, image forensics, object detection, stereo matching등 영상 뿐만 아니라 동영상, 음성 등 다양한 분야에서 활용되고 있다.
Image Melding

다만 patch match는 유사한 patch를 찾을 수 있을때는 잘 동작하지만 위 그림과 같이 비슷한 패턴을 찾을 수 없을 때는 정확하게 동작하진 못한다. 이 문제점을 해결하기 위해 patch match알고리즘의 확장형인 Image melding이 발표되었다.
※ Darabi et al., Image Melding: Combining Inconsistent Images using Patch-based Synthesis, SIGGRAPH 2012

GAN(Generative Adversarial Networks)

최근에는 이런 Image synthesis에 neural network에 적용하려는 시도가 많았고, 그 중 GAN은 가장 영향력 있는 알고리즘이라 할 수 있다. (위 사진의 인물은 모두 실존인물이 아닌 GAN이 만들어낸 영상이다.)
※ Goodfellow et al., Generative Adversarial Nets, NIPS 2014

GAN은 2개의 신경망이 서로 대립하는 구조를 가진다.
- Generator는 random 벡터를 주면 그 벡터에 맞는 새로운 이미지를 만들어준다.
- Discriminator는 이미지가 입력되면 Fake인지 Real 이미지인지 분류한다.
이렇게 두 신경망이 학습되면 Discriminator는 더욱 두 분류를 구분을 잘 하도록 학습되고, Generator는 Discriminator를 더욱 더 잘 속이기 위해서 점점 더 real한 이미지를 생성할 수 있게 학습된다.
Generator가 잘 학습됐다면 random 벡터 대신 사용자가 알고 있는 분포의 벡터를 입력해 주면 Generator를 컨트롤 할 수 있게 된다.

이 개념을 활용하면, 위 그림과 같이 Generator에 약간의 hint가 되는 input을 주면 고품질 이미지로 변환해 주는 기술로 응용할 수 있다.

우리가 기존에 regression, classification을 목적으로 하는 모델은 Discriminative model이고, Y를 잘 예측하기 위해 posterior P(Y|X)를 구하는데 관심이 있지 이미지의 분포 P(X)를 모델링 하지는 않는다.
하지만 GAN은 Generative model로 P(X)를 모델링 한 후 새로운 이미지를 생성해내는 모델이라고 할 수 있다. 특히 GAN은 두 네트워크를 대립시키면서 점점 더 좋은 Generator를 학습시키는 Adversarial training을 도입했다는 점에서 image synthesis에서 뿐만 아니라 머신러닝의 learning approach에서도 큰 성과를 이뤘다고 할 수 있다.


GAN에 존재하는 두 네트워크는 한번씩 번갈아가며 학습한다.
예를 들면 G의 파라미터를 고정시킨상태에서 이미지를 생성시키며 D의 성능을 높이고,
D의 파라미터를 고정시킨 상태에서 D를 더 잘 속이기 위해 G를 학습시키는 것이다.

위 식은 D, G를 최적화 하기 위한 목적함수를 보여준다. 목적함수는 D, G의 성능이 포함된 1개 식으로 표현되지만, 파라미터를 학습할 때는 둘 중 1개의 파라미터를 고정시킨 상태에서 각각 번갈아가며 학습시킨다.


다만 예상했듯 말처럼 학습이 쉽지는 않다. 그래서 DCGAN에서는 GAN을 안정적으로 training시키기 위한 network 설계 가이드라인을 제안하였다.
※ Radford et al., Unsupervised representation learning with deep convolutional generative adversarial networks, ICLR 2016
그리고 DCGAN에서는 random vector를 제어하는 재미있는 사례도 보여주는데,

위와 같이 안경을 쓴 여자의 사진을 생성하기 위해 각 latent random vector들의 연산을 활용할 수 있다.
Non-convergence

일반적인 네트워크 구조는 loss function을 최소화 하는데 GAN은 D, G가 각각 min, max 다른 operator를 목적으로 한다. 그러다 보니 GAN은 항상 수렴하는 것이 아니라 loss function이 진동하며 수렴하지 않는 경우가 발생한다. 간단한 예를 한번 보자.

- state 1에서 x, y가 모두 양수일 때 x는 V를 minimize하기 위해 작아지고 y는 maximize하기 위해 커진다.
- 그 결과로 다음 state에서는 x가 음수, y는 양수가 되는데 V가 음수가 됬기 때문에 서로의 목적을 달성하기 위해 튜닝된다.
위 과정을 따라가보면 알겠지만 x, y는 서로 진동하면서 특정 지점으로 수렴하지 않는다.

그러다 보니 1개의 특징만 real하게 만드는 mode collapse가 발생한다.
이 현상을 방지하기 위한 WGAN, WGAN-GP 등의 논문이 계속해서 발표되고 있다.

그 외에도 GAN의 출력 해상도를 올리기 위한 PGGAN이 있다. PGGAN은 이미지 피라미드 개념을 활용하는 개념인데, Generator가 4x4의 아주 작은 이미지를 잘 만들 수 있게 학습시고,(conv. layer1), 8x8 이미지를 잘 만들게 하기 위한 레이어(conv. layer2)를 학습시키는 방법으로 고해상도 이미지를 생성할 수 있게 한다.
DNN based Style Transfer
DNN은 활용한 몇가지 이미지 변형에 대해 알아보자.
첫 번째로 알아볼 것은 style transfer인데, 먼저 style transfer와 image-to-image translation과 구분해 보자.

Style transfer는 content image의 이미지의 style을 버리고, style image의 content를 버린 후 합치는 기술이다.

※ 사실 결국 두 기술이 목표하는 것은 같다고 할 수 있다.
Style Transfer에 대해 먼저 알아보도록 하자.
※ Gatys et al., Image Style Transfer Using Convolutional Neural Networks, CVPR 2016


이 논문의 아이디어는 CNN의 얕은 레이어로 원본 이미지를 reconstruction했을 때는 거의 원본을 복원시키지만, 깊을 수록 원본 이미지의 content가 대부분 사라진다는 것을 발견한데있다. (건물(contents)을 제대로 표현하지 못하고 영상의 느낌(style)만 남는다.) 즉, l번째 레이어는 이미지의 style이라고 가정하는 것이다.

위 식에서 변수는 아래를 의미하고,
- F^(l) : l번째 레이어의 feature map
- N^(l) : l번째 레이어의 channel 수
- i, j = l번째 레이어의 i, j번째 channel

만약 원본 이미지(☆)를 입력으로 한 l번째 레이어 feature map의 i, j번째 채널이 위와 같다고 하자. 그럼 Gram matrix식에 따라 두 이미지를 inner product 함으로써 위치 정보는 잃고 두 이미지의 similarity만 남게 된다. (style)

실제로 논문에서는 Network 가 style image, content image를 입력받으면
- style image의 style representation으로부터 계산되는는 gradient
- content image의 content와의 차이로 부터 계산되는 content representation gradient
위 두가지 gradient를 활용해 네트워크가 학습되는 것을 보여준다.
이 원리를 base로 해서,

content를 최대한 보존하고 style만 가져오기 Photo style transfer가 발표되었고,
※ Luan et al., Deep Photo Style Transfer, CVPR 2017

style transfer의 속도를 향상시키기 위해 Adaptive Instance Normalization(AdaIN)도 발표되었다.
※ Huang and Belongie, Arbitrary Style Transfer in Real-time with Adaptive Instance Normalization, ICCV 2017
이번에는 Image-to-Image Translation에 대해서 알아볼텐데,

가장 대표적인 예제는 conditional GAN을 활용한 pix2pix이다.
※ Isola et al., Image-to-Image Translation with Conditional Adversarial Nets, CVPR 2017
Generator는 random latent가 아닌 sketch를 latent로 입력받고, Discriminator는 sketch와 image를 보고 real/fake를 구분한다.

그리고 이런 img2img 모델은 위와 같이 다양한 사례에 활용될 수 있다.

이 때, style만 다르고 content는 똑같은 데이터셋이 필요하다는 어려움이 있는데, 이 문제를 해결하기 위한 방법으로 CycleGAN이 있다.
※ Zhu et al., Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Network, ICCV 2017

CycleGAN은 unpaired data를 활용해 학습하는 방법을 제안하는데, 위와 같이 일반적인 GAN구조를 사용했을 때 mode collapse가 심각하게 발생할 수 있다.
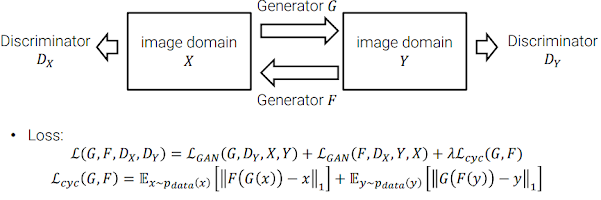
그래서 CycleGAN은 Cycle-consistency를 제안한다.
Cycle-consistency는 Y domain에서 X로가는 inverse mapping을 통해 x의 contents가 최대한 보존되게 해주며, 두 Generator G, F을 출력값을 비교해서 mode collapse를 피할 수 있다.
GAN based image manipulation
그 외에도 GAN을 활용한 사례를 몇 가지 소개한다.
GAN을 활용한 image inpainting
※ Iizuka et al., Globally and Locally Consistent Image Completion, SIGGRAPH 2017


※ Yu et al., Generative Image Inpainting with Contextual Attention, CVPR 2018

Segmentation mask만 주면 자연스러운 이미지를 만들어주는 GauGAN
※ Park et al., Semantic Image Synthesis with Spatially-Adaptive Normalization, CVPR 2019

Semantic Photo Manipulation with a Generative Image Prior
이미지에 object를 추가하거나 제거
※ Bau et al., Semantic Photo Manipulation with a Generative Image Prior, SIGGRAPH 2019

![[빅분기] PART4. 빅데이터 결과 해석 - 분석결과 해석 및 활용 - 분석결과 활용 (출제빈도 : 하)](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEj2tCMzQ5D2rhqkDfbphh9LKohFnYl3Df8LahM8gskD0BNHA5jX1MLhVIuG78S5IdyrrQrB60ygONq5FvYBLzrUnJrOhKpTfTFzZP0TFS_lZDipN44DhIq8FfFfnieRwTSzDCXvKacFQWvlcETOaoxXS0KNSFdN3apRHi5ReqUer7jCvbIFp2tj8Gmqci3S/w680/%EB%B9%85%EB%8D%B0%EC%9D%B4%ED%84%B0%20%EA%B5%AC%EC%B6%95%EB%B0%A9%EB%B2%95%EB%A1%A0%20%EB%B9%84%EA%B5%90.png)
){kind=link}
0 댓글