
Policy Gradient Methods

지금까지 true value function들을 update, estimate하는 방법에 대해서 많이 알아 봤었다. 그리고 value function을 잘 estimate 했다면 GPI(evaluation ↔ control)을 통해 optimal policy를 찾아왔었다.
이번에는 value function에 의존하지 않고 optimal policy를 찾는 방법으로 policy gradient method를 소개한다. 그리고 이 방법은 parameterized policy를 통해 학습하는 원리를 가진다.
Introduction: Policy-based RL
![]()
Policy-based RL은 policy를 parameter학습을 통해 배울 수 있는 function이라고 여기며, 학습하는 방법을 제안한다. 그리고 policy를 도출하기 위한 value function 역시도 또 다른 weight로 parameterized 되어 있다.

그전에 지금까지 배운, 앞으로 배울 내용을 잠깐 정리해보자.
Value-based
- optimal value function을 estimate하는 방법
- explicit policy가 존재하지 않는다.
- Q-learning, SARSA
Policy-based
- optimal policy를 directly 찾는 방법
- value function이 없다.
Actor-Critic
- policy(actor)와 value(critic) 두 가지 모두를 차용하는 방법
Advantages of Policy-base RL
- Stronger convergence
- high-dimensional, continuous action space에서 효과적이다.
- 사전 지식(domain knowledge)를 녹여내기가 좋다.
Disadvantages of Policy-base RL
- gradient estimate를 sampling으로 하는데, 이 때 high variance를 가질 수 있다.
- local optimum으로 수렴하기 쉬운 단점이 있다.
Outline : Policy Gradient Method

Policy gradient method의 목적은 performance를 maximize 시키는 parameterized policy π를 찾는 것이다. 그렇기 때문에 gradient ascent로 π의 parameter를 update 해줘야한다.
Policy parameterization
언급햇듯, π는 학습되기 위해 parameterized 되어야 하며 모든 state, action, parameter에 대한 gradient가 존재한다는 가정을 갖는다.
Policy Gradient method에서 policy π는 parameterized preference h(s, a, Θ)를 차용한 soft-max policy를 의미한다.

즉, 어떤 action들에 대한 확률이 학습된 파라미터 Θ로 부터 결정된다.
그럼 policy function의 성능을 결정하는 것은 parameterized preference의 복잡도 등이 있지만, non-linear model로 복잡도를 높혔을 때 그렇게 계산에 효과적이지 않음을 알고있다.
그래서 우리는 basis function을 이용한 linear technique를 이용해 parameterized linear model로 전환하는 방법을 활용할 예정이다. (on-policy prediction with approximation 포스팅에서 다루었었다.)

그리고 linear combination은 앞서 배운 basis function에 의한 feature vector를 사용해 표현된다.
※ 참고로 이 bias function은 deep learning으로 대체될 수 있다. (e.q. AlphaGo)
한 가지 예제를 풀어보도록 하자.


위 예제에서 policy π를 parameterized policy 개념으로 풀어보도록 하자.

preference h(s, a, Θ)는 정의에 따라 위와 같이 구할 수 있기때문에,

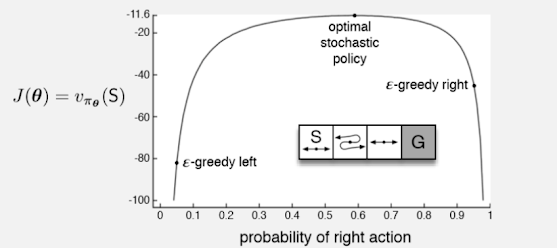
실제로 이렇게 풀었을 때 ε-greedy보다 훨씬 optimal한 policy를 찾을 수 있음을 확인할 수 있다.
Policy Object Functions
이제 policy gradient를 수행하기 위해 π자체의 quality를 구할 수 있어야 한다. 2가지 approach가 있는데,
- episodic case에서는 value of the start state를 목적함수로 두고,
- continuing case에서는 앞 시간에 배운 average reward rate per time step를 목적함수로 사용한다.

Episodic case of policy gradient

위 식의 마지막 summation항을 보면 value function의 정의와 매우 유사하다.
( vπ(s) = Σqπ(s, a) π(a | s) = 전체 action-value의 summation )
그리고 앞에 붙은 μ(s)는 on-policy distribution으로 평균을 취하기 위해 붙었다. 그럼 gradient ▽를 제거한 식은 action-value를 평가하는 식으로 볼 수 있다. (전체 action-value의 average)
즉, 위 식은 policy π를 평가하는 value function의 gradient version 으로 해석할 수 있다.
(물론 책에는 증명과정이 있지만 포스팅에서는 생략한다. 나 중에 궁금하면 아래 증명과정을 공부해보도록 하자.)



그리고 늘 그랫듯, expectation을 정확히 계산하는 어렵기 때문에, sampling을 통해서 위 식을 근사화(approximate)해보도록 하자.

- 분자 분모에 policy를 곱해주면 Σ π(a|S, Θ)qπ(S, a) 는 action-value estimate와 같기 때문에 1개 action을 sampling 한 것과 같다는 근사화 과정을 통해 2번째 줄로 표현할 수 있다.
- 그리고 qπ(S, A)의 정의에 따라 return으로 근사화 하면 아래와 같은 식으로 최종 정리할 수 있다.


이렇게 parameter를 update하는 form을 REINFORCE update 혹은 update할 때 Gt를 쓴다고 해서 Monte Carlo algorithm이라고 부른다. (Reinforce 라는 것은 고유명사로 생각하자. 큰 의미는 없다고 한다.)
[Remark]
- update되는 방향이 Gt에 proportional하고 policy에 반비례하며,
- policy probability가 증가하는 방향으로 빠르게 찾아나가는 특징을 가진다.


위 예제는 short-corridor grid world에 REINFORCE 알고리즘을 적용한 결과이며, 예상했듯 learning rate의 역할을 하는 α가 성능을 크게 좌우하는 하이퍼파라미터임을 확인할 수 있다.
정리하자면, REINFORCE는 convergence관점에서는 상당히 우수한 알고리즘이지만, MC method의 원리(Gt)를 차용했다보니, variance가 높은 단점이 있다.
그래서 그것을 보완하기 위한 방법으로 baseline을 추가하는 전략을 취할 수 있다.

여기서 b(s)는 base line이지만 Θ, s, a 모두와 상관없기 때문에 더해지든 어떻든 별로 상관없다.

그럼 위와 같이 update rule을 변경시켜주는데, 통상 baseline으로는 estimate of the state value로 설정하는 경우가 좋은 선택이 될 수 있다.

위 pseudo code를 보면 value function의 파라미터 w와 policy의 파라미터 Θ가 each step마다 update되는 것을 확인할 수 있다.

실험 결과, REINFORCE, REINFORCE with baseline은 궁극적으로 optimal로 가지만 baseline과 함께했을 때 수렴속도나 oscillation(variance) 측면에서 좀 더 긍정적인 효과를 얻을 수 있었다.
Actor-Critic Methods
앞서 포스팅 초반에 잠깐 예고했는데, Actor-Critic Method는 Value based와 Policy based 방식을 모두 차용하는 알고리즘이다.
아래는 Actor(action) only, Critic(value) only method의 특징을 보여준다.


그럼 이제 두가지 방법을 결합해보자.

위 식은 보면 π의 gradient와 action-value approximate가 함께 적용된 Actor-Critic method의 목적함수를 보여준다. (Gt 대신에 q(S, A, w)가 위치했다.)
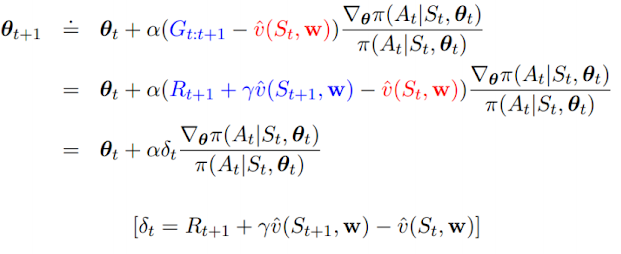
그리고 update rule을 정의하기 위해 REINFORCE 알고리즘의 Gt를 one-step return으로 대체하고, baseline을 learned state-value function으로 사용하며, 그 결과는 위와 같다.
(action-value approximate를 구하기 위해 estimate를 활용하는 bootstrap 기법을 사용한다.)

지금까지 배운 policy gradient들을 쭉 정리하면 아래와 같다.

- 1) REINFORCE
- 2) Action-value Actor-Critic
- 3) Advantage Actor-Critic
- 4) TD(0) (One-step) Actor-Critic method
※ 이 것들 외에도 굉장히 다양한 gradient들이 있는데 그 목적은 일맥상통한다.
Policy Gradient for Continuing Problem
앞서 배운 average rate of reward를 떠올려보자.

그리고 continuing case에서는 value를 아래와 같이 differential return으로 표현할 수 있다.

![]()
continuing case에서의 증명도 아래와 같이 있으니 시간이 나면 살펴보도록 하자.


예를 들어 Gaussian policy를 보자.


Gaussian으로 모델링한다는 것은 평균과 분산을 parameterized 시키는 것이다.

Summary
- action-value를 구하지 않고 parameterized policy를 직접 학습해서 action을 selection하는 방법을 배웠다. (Policy gradient method)
- 파라미터를 update하는 rule을 여러개 배웠는데, 이 방식은 policy의 probability가 증가하는 방향으로 update되는 것을 확인했다.
- policy gradient theorem의 대표적인 REINFORCE, Actor-Critic을 배웠다.
- REINFORCE는 policy gradient를 directly 학습하는 방법이고 baseline을 통해 variance를 줄일 수 있다.
- Actor-Critic은 value function(critic)과 policy(actor)를 모두 update에 활용하는 방법이다.
- 두 theorem은 절대적으로 어떤 알고리즘이 더 좋다기 보단 서로 장단점이 있어 상황에 맞게 사용하면 된다.
![[빅분기] PART4. 빅데이터 결과 해석 - 분석결과 해석 및 활용 - 분석결과 활용 (출제빈도 : 하)](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEj2tCMzQ5D2rhqkDfbphh9LKohFnYl3Df8LahM8gskD0BNHA5jX1MLhVIuG78S5IdyrrQrB60ygONq5FvYBLzrUnJrOhKpTfTFzZP0TFS_lZDipN44DhIq8FfFfnieRwTSzDCXvKacFQWvlcETOaoxXS0KNSFdN3apRHi5ReqUer7jCvbIFp2tj8Gmqci3S/w680/%EB%B9%85%EB%8D%B0%EC%9D%B4%ED%84%B0%20%EA%B5%AC%EC%B6%95%EB%B0%A9%EB%B2%95%EB%A1%A0%20%EB%B9%84%EA%B5%90.png)
0 댓글