
Normalization

예를 들어 이미지 데이터의 경우 픽셀 정보를 0~255 사이의 값으로 가지는데, 이를 255로 나누어주면 0.0~1.0 사이의 값을 가지게 될 것이다. 이런 행위를 feature들의 scale을 정규화(Normalization)한다고 한다.
그럼 정규화를 했을 때 장점은 어떤 것이 있을까? 바로 optimal solution으로의 수렴 속도가 빨라진다는 것다.


[출처 : Geoffrey Hinton 강의 자료]
위와 같이 loss를 w1과 w2를 축으로 하는 parameter space에서 표현하고, optimal이 원점에 있다고 하자. 확실히 정규화 전에는 loss function의 형태가 Elongated(가늘고 길죽한)되어 있지만 정규화 후에는 Spherical(구 모양)해 졌다.

그럼 이 정규화의 효과를 딥러닝 구조에 적용해보도록 하자.
그런데 딥러닝은 input layer에서 정규화된 값을 입력하더라도, weighted sum과 activation function을 거치면서 다시 비정규화된 형태로 변경될 것이 분명하다. 이 때 우리 선택지는 각 노드별로 다시 정규화해줄지, 혹은 표준정규분포를 갖게 해줄지, 아니면 layer들을 묶어서 모든 node가 같은 scale을 갖게 정규화해줄지 등의 선택지가 있다. 그에 따라 아래와 같이 정규화 방법을 구분하기도 한다.
- Batch normalization : CNN에 많이 사용하는 기법
(Batch normalization: Accelerating deep network training by reducing internal covariate shift, ICML, 2015)
- Layer normalization : RNN에 많이 사용하는 기법
(Layer normalization, Preprint arXiv, 2016)
- Instance normalization : Computer vision에서 많이 사용하는 기법
(Instance normalization: The Missing Ingredient for Fast Stylization, Preprint arXiv, 2016)
- Group normalization
(Group normalization, Preprint arXiv, 2018)
정리하자면, 어떤 기준을 삼느냐에 따라 정규화(normalization) 방법이 나눠질 순 있지만 원리는 크게 다르진 않다. 그 중 가장 근간이 되는 Batch normalization에 대해서 중점적으로 다루고, 다른 normalization 방법에 대해 간단히 알아보도록 하자.
Batch Normalization
Gradient vanishing / exploding
Batch normalization을 설명하기 전에 딥러닝의 가장 근본적인 문제였던 vanishing / exploding gradient problem에 대해서 잠깐 이야기하자.
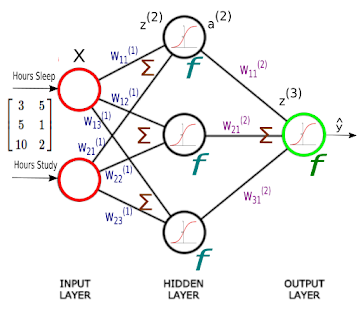
예전에 activation function은 0~1사이 값을 갖는 sigmod 함수를 사용했었다. 그리고 신경망의 파라미터의 학습은 back propagation에 의해 진행된다. 그리고 앞서 Back propagation은 input layer 방향으로 편미분을 연쇄적으로 한다는 것을 앞 시간에 다루었다.

[Ranking to Learn and Learning to Rank:
On the Role of Ranking in Pattern Recognition Applications, 2017]
그런데 Sigmoid 함수나 Tanh함수를 미분하면 위 그림의 (a), (b)와 같이 입력의 절대값이 큰 구간에서는 gradient가 0으로 수렴한다. 이게 hidden layer가 1개 정도면 무시할만한데, 여러층이라면 input layer의 gradient가 모두 0으로 수렴하면서 파라미터 튜닝이 불가능해진다.
이렇게 back propagation중 gradient가 사라지는 현상을 gradient vanishing 문제라고 하는데, 이 문제를 해결하기 위해 gradient가 0으로 사라지지 않도록 ReLU(c), Softplus(d) 와 같은 activation function이 등장했다. 하지만, 이 방법은 본질적인 gradient vanishing의 해결방법이 아니라 간접적으로 회피하는 트릭으로 볼 수 있다. (실제로 층이 깊어지면 똑같은 문제가 발생한다.) 마찬가지로 dropout이나 regularization과 같은 기법역시 본질적인 문제를 해결하지 못한다.
Internal Covariance Shift
그러다가 2015년에 arXiv와 ICML에서 발표된 획기적인 방법이 바로 Batch normalization이다. 논문의 저자는 위에서 해결하고자 하는 문제의 근본적인 원인을 Internal Covariance Shift로 보고 있다.

Internal Covariance Shift 현상은 위 그림처럼 아무리 input layer에서 정규분포를 가지는 입력을 줘도 hidden layer를 지나면서 그 분포가 점점 정규분포를 벗어나는 것을 의미한다.

위 그림으 4번째 노드의 경우는 상당히 우측으로 치우쳤는데, 저 상태에서 back propagation을 하면 대부분의 분포가 gradient = 0부근(빨간 구역)에 집중되어 있기 때문에 gradient vanishing 현상이 발생한다.
Batch normalization
이 현상을 막기 위한 가장 간단한 방법은 매 순간 input을 평균 0, 표준편차 1인 분포로 normalization 시켜 주는 것이며 이 행위를 whitening라 하기도 한다. (표준정규분포를 만들어 주는 것. Standardization) 아래는 샘플을 표준정규분포로 만드는 방법인데 데이터마이닝 시간에 충분히 다루었음으로 자세한 설명은 생략한다. (

여기서 '매 순간'의 의미는 weight가 training되는 순간이다. 즉, 매 mini-batch마다 whitening 하는 기법이 바로 Batch normalization 이다.
큰 개념은 위와 같은데, whitening은 위에서 말한 것 처럼 단순히 standardization 하는 것만은 아니다. (이렇게 단순하다면 거창하게 batch normalization 이라 이름 붙지도 않았을것이다.)

일단 BN(Batch Normalization)은 activation function이 작용하기 전 즉, pre-activate상태 a에서 아래와 같이 2단계로 진행된다.

- Normalize pre-activation function : pre-activate 된 샘플을 standard normalize 한다.
- Scale and shift : standard normalize 된 샘플의 variance와 bias를 조절할 수 있는 γ, β를 부과해서 parameterize 한다.
위 과정 중 두번째 과정에서 variance와 bias를 다시 조절하는 이유는 sigmoid의 경우는 중심에 분포가 몰려 있는 것이 효과적이지만, 다른 activation은 그렇지 않기 때문이다. 즉, 학습을 통해 γ와 β를 학습해 적절한 분포를 가지게 하기 위함이다. 결과적으로 γ와 β라는 새로운 학습 파라미터를 추가로 생성한 것이 Batch normalization의 핵심다.
※ ε는 분모가 0이 되는 경우를 방지하기 위한 아주 작은 상수이다.
BN in Inference Phase
그런데 test는 batch로 주어지지 않고 1개 샘플만 입력된다. 즉, batch별 평균과 분산을 구할 수 없다. 이 경우를 방지하기 위해 배치별로 구해뒀던 평균과 분산을 버리지 않고 메모리에 기억해뒀다가 Test data를 Inference할 때 재사용한다. 아래는 위 과정을 수식화 한 것이다.

Benefit
2015년에 발표된 논문 "Batch normalization: Accelerating deep network training by reducing internal covariate shift(ICML, 2015)" 에서 주장하는 장점은 다음과 같다.
- Batch normalization을 사용할 경우 back propagation 시 parameter의 scale에 영향을 받지 않는다. 그래서 learning rate를 크게 잡을 수 있게 되고, 이는 빠른 학습을 가능하게 한다.
- Batch normalization의 경우 자체적인 regularization 효과가 있다. 그래서 L1, L2 regularization이나 Dropout 과정을 생략할 수 있다. 참고로 Dropout의 경우 효과는 좋지만 학습 속도가 다소 느리다는 단점이 있는데 이를 제거함으로써 학습 속도가 향상되는 효과도 얻을 수 있다.


위 Figure는 실제로 CNN 알고리즘에 batch normalization을 적용해서 수렴 속도를 test해본 결과이다. 위 연구에서도 실제로 수렴 속도 / dropout 생략 / L2 regularization 생략 등의 효과가 있었다고 한다.
Other Normalization
Layer normalization

batch normalization에서는 mini-batch 샘플의 feature별 평균과 분산을 구해서 표준정규분포로 전환했다. (각 노드별로) 그런데 batch size가 1이라면 불가능한 문제점이 있다. (1개 샘플로 평균과 분산을 구하기 어렵기 때문)
※ 위 그림의 세로축은 features, 가로축은 batch를 의미한다.
layer normalization은 이 문제점을 해결하기 위해 batch에 있는 모든 feature의 평균과 분산을 구한다. 즉, 각 hidden node의 feature별 평균과 분산이 아닌 hidden layer 전체의 평균과 분산으로 normalization한다. 그 이후의 과정은 batch normalization과 완벽히 동일하다.
Instance Normalization, Group Normalization
위 그림은 CNN에서 normalization하는 방법을 도식화 한 것이다.
※ 이미지의 Height, Width를 1 차원으로 합치고, Channel C와 N개의 Batch로 도식화
위 그림에서 파란색으로 highlight된 부분은 평균과 분산을 구해 normalization 하는 영역이다.
실제로 Batch Norm.에서는 배운대로 batch 샘플 별 평균과 분산을 구하는 것을 확인할 수 있다.
반면 Layer Norm.에서는 모든 Channel의 평균과 분산을 구하기 때문에 1개 batch에서도 동작할 수 있다. (Feature 차원의 normalization)
Instance Norm.은 1개 batch내의 각 Channel 마다 평균과 분산으로 normalization하는 방법이다. (CNN이니까 가능한 기법이다. real-time generation에 효과적이라고 한다. style transfer을 위해 고안된 방법.)
Group Norm.은 Batch Norm을 하고 싶은데 segmentation, video와 같이 메모리 소비때문에 어쩔 수 없이 batch size가 제약될 때 대체하기 위한 방법이다. 채널을 그룹지어 그룹 단위로 normalization 한다. 만약 그룹이 채널 전체면 Layer norm, 그룹이 채널 하나면 Instance norm이 된다.


[이미지 출처 : "Group normalization" Preprint arXiv:1803.08494]
![[빅분기] PART4. 빅데이터 결과 해석 - 분석결과 해석 및 활용 - 분석결과 활용 (출제빈도 : 하)](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEj2tCMzQ5D2rhqkDfbphh9LKohFnYl3Df8LahM8gskD0BNHA5jX1MLhVIuG78S5IdyrrQrB60ygONq5FvYBLzrUnJrOhKpTfTFzZP0TFS_lZDipN44DhIq8FfFfnieRwTSzDCXvKacFQWvlcETOaoxXS0KNSFdN3apRHi5ReqUer7jCvbIFp2tj8Gmqci3S/w680/%EB%B9%85%EB%8D%B0%EC%9D%B4%ED%84%B0%20%EA%B5%AC%EC%B6%95%EB%B0%A9%EB%B2%95%EB%A1%A0%20%EB%B9%84%EA%B5%90.png)
{kind=link}
1 댓글
안녕하세요 덕에 좋은 정보 많이 얻어갔습니다. 그런데 글을 읽다가 궁금증이 생겼는데
답글삭제batchnormalization 은 batch_size =64라면 64장에 대한 평균과 분포의 변수 데이터를 만들고
instance Normalization 은 각 채널마다 평균과 분포가 생긴다 하셨는데.
그럼 두 개의 차이는 여러 이미지에서 평균과 분포를 구하느냐 혹은 한개의 이미지에서 평균과 분포를 구하느냐 이 차이인가요?
그렇다면 이 두 개에 어떤 장단점이 있는지 궁금합니다.