
Multilayer Perceptrons

Perceptron은 최근 주목받고 있는 Neural Network, Deep learning의 조상뻘 되는 알고리즘이다. 실제로 Python에서 누구나 한번쯤 사용해봤을 scikit-learn 라이브러리에서도 인공신경망을 구현하는 알고리즘의 이름이 MLPClassifier/Regressor으로 등록되어 있다. 더욱 놀라운 것은 이 알고리즘이 최근에 빛을 보고 있긴 하지만 Perceptron의 최초 구현은 1957년이라는 것이다. (Frank Rosenblatt, 1957)
이 유서 깊은 알고리즘이 현재는 Deep Learning이라 불리며 Universal approximation, 즉 왠만한 모든 함수를 근사화 할 수 있는 것으로 알려져 있다. 이번 시간은 Neural network를 소개하는 시간으로, 최소한 Perceptron, Backpropagation 에 대해서는 확실히 짚고가도록 하자.
Perceptron
Perceptron은 binary linear classification 문제를 풀기 위해 모델을 iterative하게 학습한 최초의 알고리즘이다.


linear classification은 서로 다른 분류를 구분 할 수 있는 linear 하이퍼플레인(hyperplane)을 찾는 것이다. 위 경우 affine function을 찾을 수 있다면 그 함수를 기준으로 크거나 작은경우를 나눠서 sign function에 적용하면 binary linear classification이 가능하다.
※ 참고로 두 분류를 구분할 수 있는 함수를 2차원에서는 line, 3차원은 plane, 3차원 이상에서는 hyperplane으로 정의한다.

![]()
Frank Rosenblatt은 '만약 두 분류가 linear separable하다면, mistake-driven procedure를 통해 정확히 두 분류를 구분할 수 있는 perceptron을 만들 수 있다.'는 것을 증명했다. 그 원리는 아래와 같다.


만약 weight를 잘 찾았다면 class1일 때 wx > 0, class2일 때 wx < 0 으로 계산되어야 한다. 이걸 한줄로 표현하면 아래와 같다.
실제로 위 2가지 가정을 대입하면 항상 0보다 큰 것을 확인할 수 있다.
그럼 이제 weight vector w를 찾기 위해 오차함수를 정의해야 한다.
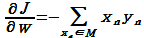
(아마 최초의 gradient decent 등장이었지 않았을까 생각된다.)
실제로 Perceptron이 동작하는 순서는 아래와 같다.
- sample을 1개 불러온다
- 현재 weight를 적용해 맞는지 틀리는지 확인한다.
- 맞으면 아무것도 안하고- 틀리면 x*y를 더해준다. (틀리면 x*y< 0)
- 수렴할 때까지 반복한다.
참고로 샘플 1개 → weight 1번 update하면 batch size = 1라고 표현한다.
샘플 2개당 1번 update할 수도 있다. (batch size = 2)
이렇게 하는 이유는 데이터가 방대하게 많을 때 weight를 좀더 빨리 update시킬 수 있는 속도측면의 장점, 전체 에러를 기억할 필요가 없으니 메모리 관리 측면의 장점 등이 있다. 추후에 더 자세히 다루도록 한다.
Multi-layer Perceptron

그런데 앞에서도 살짝 말했지만, 이 알고리즘은 linearly separable 해야만 성립한다. 역으로, linearly separable 하지 않으면 perceptron 1개로는 XOR 문제조차 풀지 못한다는 것이 증명되었다. (Minsky, 1969)



Rosenblatt이 제안한 perceptron는 output에 관련된 직전 input의 gradient를 구해서 weight를 튜닝하는 방법이었다. 즉, 위 그림에서 output error가 계산됐다면 w2를 튜닝할 순 있지만 w1을 튜닝시킬 방법이 없다는 것이다. 왜냐하면 Input layer입장에서는 Hidden layer에 있는 값이 맞는지 틀렸는지 알 수 있는 방법이 없기 때문이다. 그래서 등장한 개념이 Backpropagation인데 조금 있다가 자세히 다루도록 한다.
McColloch-Pitts Model
사실 앞에서도 보여줬던 이 그림은 처음부터 Rosenblatt이 제안한 모양은 아니었다. 그 때는 Activation function이라는 것도 없었고, binary classification을 하기 위한 sign function만을 사용하던 시기였다.


McColloch와 Pitts는 우리 뇌의 신경세포가 특정 조건에만 활성화 되는 것을 확인하였다. 그래서 perceptron에 weighted sum과 activation function의 개념을 적용시켰다.
가장 대중적인, 초창기 activation function은 sigmoid 형태의 함수다. 위 그림에도 나와있듯, 특정 조건이 충족되면 0→1로 전환되는 함수다. (실제 뇌에서 특정 조건을 달성해야 뉴런이 활성화 된다.)
그 외에도 아래와 같은 다양한 함수들이 있는데, sigmoid, ReLU가 가장 대중적으로 쓰인다.(실제로 성능도 좋다.)
※ ReLU의 단점을 보완하기 위한 Leaky ReLU, ELU, Softplus, ReLU-6 등이 있지만 큰 성능차이는 나지 않는다고 한다. 다양한 종류들이 있다는 것 정도는 알아두자.

Backpropagation
Rosenblatt이 제안한 perceptron는 output에 관련된 직전 input의 gradient를 구해서 weight를 튜닝하는 방법이었다. 즉, 위 그림에서 output error가 계산됐다면 w2를 튜닝할 순 있지만 w1을 튜닝시킬 방법이 없다는 것이다. 왜냐하면 Input layer입장에서는 Hidden layer에 있는 값이 맞는지 틀렸는지 알 수 있는 방법이 없기 때문이다.
그래서 등장한 개념이 Backpropagation이다. Backpropagation은 「역전파」로 해석되며, neural network에서는 「파라미터가 오차에 얼마나 영향을 미쳤는지 파악」하기 위해 사용되어 오차역전파라 부른다.
다시한번 정리하자면, Backpropagation은 파라미터가 오차에 미친 영향 δL/δw 즉, parameter space에서의 gradient를 구하는 것이다. 그리고 그 원리는 output layer에서 발생한 오차를 input layer 쪽으로 편미분하며 전파시키는 것이다.
Backpropagation을 이해하기 위한 아주 쉬운 예제를 한번 보자.

위와 같은 함수를 Computational graph로 그려보았다. 나눌 수 있는대로 각 항을 U, V, J라고 이름을 붙였다. Forward propagation은 그냥 대입하면 되니 이해하는데 그렇게 어렵지는 않을 것이다. 이제부터가 중요하다.

- δJ/δa = δJ/δV * δV/δa 이다. (chain rule)
- J를 V에 대해 편미분하면 δJ/δV = 3이다.
- V는 a에 대해 편미분하면 δV/δa = 1이다.
- 두 값을 곱하면 δJ/δa = δJ/δV * δV/δa = 3이다.
- 즉, a가 J에 미친 영향은 3이다. (a가 1단위 증가하면 J는 3증가한다.)
위 방법을 그대로 linear regression의 오차함수에 적용해보자.

- w1, w2는 초기값 혹은 학습되어 있으니 상수다.
- y^도 w1, w2에 의해 예측될 수 있으니 상수다.
- x1, x2, y도 관측되는 sample이니 상수다.
- 그럼 w1, w2가 J에 미치는 영향(gradient)를 chain rule로 구할 수 있다.

- Forward propagation: 맞든 틀리든 일단 예측한다.
- Error function : 예측결과로부터 오차를 파악한다.
- Back propagation: 파라미터들의 gradient를 구한다.
- Optimization : gradient decent를 통해 파라미터를 튜닝한다.
- Iteration : 오차가 충분히 작거나 지정한 반복횟수만큼 반복한다.
![[빅분기] PART4. 빅데이터 결과 해석 - 분석결과 해석 및 활용 - 분석결과 활용 (출제빈도 : 하)](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEj2tCMzQ5D2rhqkDfbphh9LKohFnYl3Df8LahM8gskD0BNHA5jX1MLhVIuG78S5IdyrrQrB60ygONq5FvYBLzrUnJrOhKpTfTFzZP0TFS_lZDipN44DhIq8FfFfnieRwTSzDCXvKacFQWvlcETOaoxXS0KNSFdN3apRHi5ReqUer7jCvbIFp2tj8Gmqci3S/w680/%EB%B9%85%EB%8D%B0%EC%9D%B4%ED%84%B0%20%EA%B5%AC%EC%B6%95%EB%B0%A9%EB%B2%95%EB%A1%A0%20%EB%B9%84%EA%B5%90.png)
0 댓글