
Anomaly Detection
Anomalies
Anomalies라는 것은 noise는 아니지만 예상하는 패턴에 부합하지 않는 데이터를 의미한다.

- Point anomalies : 1 point씩 군집에 포함되지 못하는 데이터

- Contextual anomalies : 전 history에 영향을 받은 특이 데이터

- Collective anomalies : 평소와 다른 패턴이 나오는 데이터
Anomaly (outlier) Detection Example

사실 Anomaly는 위 그림과 같이 정상인 데이터의 distribution을 잘 모델링하면 잘 찾을 수 있다. 위 예제에서는 정상데이터의 분포를 넘어선 샘플들을 Anomaly로 인식한 것을 보여준다.
이 때 중요한 것은 정상데이터의 분포 P(x) 모델링,
그리고 Anomaly로 선택할 기준인 threshold ε의 선택이라고 할 수 있다.
위 과정을 되새겨보면, 어느 누구도 Anomaly를 제안하지 않는다.
즉, Anomaly detection은 training data x만으로 분포를 학습하는 전형적인 unsupervised learning이다.
혹은 1개 normal class만 학습한다고 해서 one-class learning 혹은 one-class classification이라고도 한다.
Anomaly detection vs. Binary classification
이 쯤 되면 한가지 의문이 든다.
- Binary Classification
1) Well balanced : Positive와 Negative 샘플의 비율이 비슷하다.
2) Similar : Training에서 Pos./Neg.의 분포가 Test(현실)에서도 비슷하다.
- Anomaly Detection
1) Severely imbalanced : Positive나 Negative 샘플만 많다.
2) Very different : 시간이 지나면서 또 다른 Negative 패턴이 나타날 수 있다.
→ 그래서 정상범주의 분포를 잘 학습하고 그 외의 범주를 Anomaly로 detect하는 것이 더 효과적이다.
(보통 Anomaly데이터 수가 적기도 하지만, 괜히 Anomaly의 패턴을 학습했다가 새로운 패턴에 대응하지 못하는 문제점이 생긴다.)
Gaussian Models for Anomaly Detection


정상 데이터가 Gaussian 분포를 따른다고 가정하고 Gaussian distribution model P(x)을 찾는것이 가장 기본적인 접근방법이고, 직관적이고, 구현하기도 쉽다.

왜냐하면 Gaussian 분포의 Probability density function(PDF)은 평균과 분산을 이용해 closed-form으로 표현될 수 있기 때문이다.
closed-form으로 표현할 수 있다는 것은 자유자재로 미분, 적분이 가능하다는 뜻이기때문에 모델링에도 적합하다

그래서 많은 사람들이 문제를 Gaussian density function으로 나타내기 위해 Marginal Independence를 가정하거나,

이렇게 Gaussian 분포로 데이터를 표현할 수만 있다면,

Anomaly Detection in High-Dimensional Data

PCA(Principle Component Analysis)는 대표적인 feature extraction 알고리즘이다.
(PCA의 자세한 원리는 [데이터마이닝 : 변수 선택법]을 참고하자. 이번 포스팅에서는 PCA를 벡터연산을 통해 증명하는 과정은 생략한다.)
그래서 다차원의 공간의 중요한 feature를 찾아내서 작은 차원으로 축소하는데 가장 많이 활용된다. 실제로 위 예제는 2차원의 공간을 1차원의 공간(녹색 실선)으로 projection한 결과를 보여준다. (○로 표현되던 데이터를 ●으로 projection 시켰다.)
이 원리를 이용하면 Anomaly Detection에도 활용할 수 있다.

PCA로 새로운 차원으로 데이터를 projection 시킬 때, 새로운 차원에서의 데이터 분포를 위와 같이 가시화 할 수 있다.
이 때 원본 데이터는 분포의 평균에서 멀거나(Rank-K projection distance)
새로운 projection 라인과 직교 거리가 멀 수 있다. (Rank-K leverage scores)
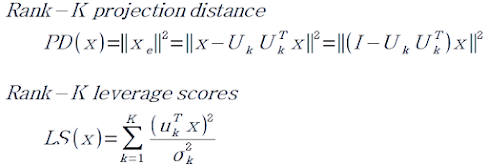
![]()
위 두 score는 위와 같이 계산 될 수 있는데, 이 두 score를 구할 수 있으면, 각각 threshold를 지정해 간단하게 Anomaly를 detecting 할 수 있다.
Anomaly Detection with Auto-encoder

정상 데이터를 encoder에 학습시키고, reconstruction error가 크면 anomaly로 판단하는 방법이다. (Anomaly detection에서 가장 인기 있다.)
새로운 데이터를 encoder에 입력시키면 decoder가 새로운 데이터을 생성하는데, 그걸로 reconstruction error를 구한 다음 판단한다.
Anomaly Detection in Time Series

Input Sequence와 최대한 똑같은 Reconstructed Sequence를 예측하도록 학습하고, 이 때 에러를 anomaly의 기준으로 삼는 방법이다.

LSTM EncDec-AD도 유사한데, 개인적으로 RNN의 성능이 아직은 미덥지 않아서 사용하긴 힘들지 않을까 조심스레 생각해본다.
GANs for Anomaly Detection

Autoencoder도 AD를 할 수 있는데 GAN이라고 못할 건 없다. 다만, encoder가 있어야 하는데 GAN은 decoder(generator)밖에 없다.
그럼 encoder를 만들어 주면 된다. 그리고 discriminator가 encoder vs. decoder를 보고 outlier를 탐지한다. 그래서 BiGAN이라고도 많이 불린다. (사실 encoder도 generator에 해당하기 때문)
![[빅분기] PART4. 빅데이터 결과 해석 - 분석결과 해석 및 활용 - 분석결과 활용 (출제빈도 : 하)](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEj2tCMzQ5D2rhqkDfbphh9LKohFnYl3Df8LahM8gskD0BNHA5jX1MLhVIuG78S5IdyrrQrB60ygONq5FvYBLzrUnJrOhKpTfTFzZP0TFS_lZDipN44DhIq8FfFfnieRwTSzDCXvKacFQWvlcETOaoxXS0KNSFdN3apRHi5ReqUer7jCvbIFp2tj8Gmqci3S/w680/%EB%B9%85%EB%8D%B0%EC%9D%B4%ED%84%B0%20%EA%B5%AC%EC%B6%95%EB%B0%A9%EB%B2%95%EB%A1%A0%20%EB%B9%84%EA%B5%90.png)
0 댓글