
Deep Generative Models - Implicit

Deep Generative Model의 두 가지 접근법 중 Implicit model은 확률 분포 파라미터를 학습하는 것이 아니라, 단지 원본데이터와 예측데이터의 분포가 비슷하도록 Generation하는 방법이다.
GAN (Generative Adversarial Networks)
GAN은 Implicit model 들 중 가장 인기있는 모델로 알려져 있고, 2018년에는 10 Breakthrough Technologies에 선정될 만큼 많은 사람들의 관심을 받고 있다.
GAN의 원리
GAN은 Generative Adversarial Networks라는 이름에서 알 수 있듯, 적대적(adversarial) 관계인 두 네트워크를 이용하는 방법이다.

위 그림은 일반적인 GAN의 구조를 도식화한 것이다.
- Generator : 최대한 원 데이터와 비슷한 데이터(Fake)를 생성하는 네트워크
- Discriminator : Fake 데이터가 들어왔을 때 Fake라고 분류하는 Binary Classifier
GAN은 Generator와 Discriminator가 열렬히 싸우도록 만든다.
마치 adversarial game처럼 Generator는 Discriminator를 이기기 이해 더욱 Real에 가까운 Fake 데이터를 생성해내고, Discriminator는 Fake/Real을 더욱 정확하게 분류하기 위해 학습한다.
GAN의 목적함수를 보면 더욱 명확하다
만약 D가 Fake/Real을 아주 구별을 잘 하는 모델이고, x가 Real이라면 D(x)=1 이므로 첫번째 log term이 사라진다. 즉, 이 때가 G입장에서 가장 성능이 좋을때다 (min)
반대로 G(z)가 만들어낸 값이라면 D(G(z))=0 이므로 두번째 log term이 사라진다. 즉 이때가 D입장에서 가장 성능이 좋을 때다. (max)
만약 이 목적함수가 더 이상 파라미터를 튜닝하지 않으면,
즉, 한 명만 계속해서 이기기 시작할 때(Nash equilibrium) 학습이 완료된 것이다.
참고로 D와 G의 성능을 동등하게 유지하며 싸우게해줬을 때 GAN의 성능이 가장 좋다.

(D의 성능은 점점 떨어지고 G의 성능은 점점 좋아진다.)
- 검은 점선 : Real data의 분포 (p_data)
- 녹색 실선 : Generator의 분포 (p_g)
- 파란 점섬 : Discriminator의 분포 (p_d)
하지만 학습을 지속하면서 두 분포는 가까워지고, Discriminator는 점점 구분을 못하면서 마지막에는 전혀 구분을 못하는 상태 D(x) = 0.5 가 된다.
지금까지 설명한 방법이 가장 standard한 GAN의 학습방법이다.
물론 GAN이 VAE에 비해 학습이 까다로운 것은 사실이다.
(그래도 VAE에 비해 훨씬 깔끔한 이미지를 얻을 수 있는 강한 장점이 있다.)
왜냐하면 D를 위한 maximize도 해야하고 G를 위한 minimize도 해줘야 하다보니 gradient를 update할 때 어려움이 있기 때문이다.
이 문제를 해결하기 위해 많은 시도가 있었지만 대표적인 2가지 정도만 소개한다.
1) Feature Matching to Train G [T.Salimans et al. (2016)]
위 식의 의미를 해석해보면 결국 x와 z의 차이를 최소화 하는 것이다.
하지만 위와 같이 x와 z의 직접적인 차이가 아니라 각 feature의 차이를 최소화 하는 목적함수를 새로 정의하면 D(G(z))와 같이 coupled된 항이 풀리면서 gradient를 구하기 더 수월해진다.
2) GAN Trained with Denoising Feature Matching
[D. Warde-Farley and Y.Bengio (2017)]
학습할 때는 noise를 섞고, error를 구할때는 clean한 x를 이용해서 구하는 방법이다.
(Denoising Autoencoder + Discriminator)
이렇게 했을 때 training이 잘 될 뿐아니라 overfitting도 방지할 수 있다고 한다.
Generating Images by GANs
Generator는 random noise input z를 입력받는데, z를 조금씩 변형시키면서 Generator를 거치면 아래와 같은 현상이 나타난다.
![]()

이런 원리를 활용하면 위 예제처럼 사람의 표정이나 성별 등을 미세하게 변경시키며 수많은 이미지를 generation 할 수 있다.
(아직 어디에 활용해야할지는 잘 모르겠지만 high technology임은 분명하다.)
Other approaches
GAN은 2014년에 처음 발표되면서 새로운 학습방법으로 떠오르며 많은 사람들의 관심을 받았다.
물론 이 때 GAN이 완성형태가 아니었는만큼 GAN을 활용한 다양한 연구가 지금까지도 진행되고 있는데, 몇 가지 주요 모델들을 소개한다.
1) DCGAN
(lec Radford, Luke Metz, and Soumith Chintala (2015) "Unsupervised representation learning with deep convolutional generative adversarial networks." Preprint arXiv:1511.06434)

주로 이미지를 Generate할때 사용하는 모델은 DCGAN이다. (Deep Convolutional GAN)
DCGAN은 100차원의 random noise vector z를 이용해서 64x64 크기의 이미지를 생성하는 모델이다. (조금 뒤에 실습으로 구현할 예정이다.)
2) Progressive Growing of GANs
(Tero Karras, Timo Aila, Samuli Laine, and Jaakko Lehtinen (2018), "Progressive growing of GANs for improved quality, stability, and variation," ICLR)
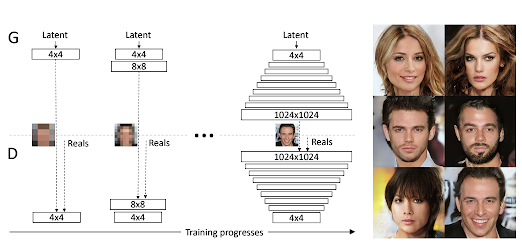
높은 해상도의 이미지를 DCGAN을 통해 학습하고 생성하는데는 많은 비용이 든다. 이 논문에서는 4x4 낮은 해상도의 latent variable로 시작해서 1024x1024로 키워나가는 기술을 다룬다.
Fixed layer를 가졌을 때에 비해 학습시간을 획기적으로 낮춘 방법으로 알려져 있다.
3) GAN for single image super-resolution
(Christian Ledig et al. (2016), "Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network," Preprint arXiv:1609.04802)


Image processing 분야에서 예전부터 활발한 연구분야인 super-resolution에도 GAN을 적용할 수 있다.
Discriminator가 일반적인 이미지인지 super-resolution 이미지인지 분류하는 역할을 하고, Generator는 Discriminator를 이기기 위해 super-resolution 이미지를 생성한다.
Conditional GAN
지금까지 배운 GAN으로는 학습이 완료된 후에 random latent variable을 던져주면 Generator가 알아서 이미지를 만들어서 줬다.
그럼 만약에 내가 원하는 이미지를 생성하고 싶으면 어떻게 해야할까?
예를 들어 MNIST데이터를 GAN으로 학습하고, 내가 숫자 3을 표현하는 latent 변수를 입력으로 주면 숫자 3을 표현하는 이미지를 생성하고 싶은 것이다.

방법은 생각보다 간단하다. Encoder를 학습할 때 input의 차원을 늘려서 label과 함께 학습하게 하고, Decoder로 생성할 때도 z의 차원을 늘려서 condition vector를 함께 입력하는 것이다.

MINIST데이터를 예로 들면, 64x64x1 의 크기를 가지는 이미지에 10개 차원을 추가해서 64x64x11 이미지를 학습하는 것이다. 이 때 2~11번째 차원은 0~9를 인식할 수 있는 one-hot encoded vector를 적용할 수 있다.
Unpaired Image to Image Translation

지금까지 배운 내용으로는 Paired 이미지를 변환하는 것은 가능하다. 예를 들어 edge만 있는 이미지를 Generator의 latent variable로 입력했을때 학습된 분포에 따라서 색을 입혀주는 것은 지금까지 배운것으로도 충분하다.
그런데 Unpaired 이미지, 예를 들어 임의의 사진을 고흐풍으로 변환하는 작업에는 어떻게 GAN을 활용할 수 있을까? 이런 고민을 해결하기 위해 제안된 것이 바로 Cycle-Consistent Adversarial Network다.

예를들어 사진이 X, 고흐의 paining을 Y라고 하자.
이 때 위 그림의 G는 사진을 고흐풍으로 만드는 Generator, (X→Y)
F는 고흐풍 그림을 사진으로 변환하는 Generator 된다.(Y→X)
그리고 특정한 사진 X를 집어서 고흐풍 그림 Y를 만들고, 그 그림으로 다시 X를 만든다고 가정하자.
이 때 X의 차이 (Cycle consistency loss)를 최소화 한다면 고흐풍 그림을 잘 만든 것인데,
이런 목적함수를 가지는 것이 바로 CCAN이다.
그리고 Generator의 구조가 CNN이라면 Image Transfer로 활용할 수 있는데,
만약 RNN이라면 모짜르트풍의 음악을 만드는 Music Generator가 될 수도 있다.
지금까지 2번의 포스팅을 통해 Deep Generative model을 살펴봤는데,
솔직히 아직은 제조업 어떤 분야에 활용을 할 수 있을지는 바로 떠오르지 않는다.
몇 가지 생각나는 것은,
- 평소 조업 패턴을 GAN으로 학습시킨 후, 유사한 조업패턴을 생성하게 하여 사람의 직관을 모델링 하는 것
- Database 군데군데 있는 결측치들을 평소 패턴과 유사한 값으로 보정하는 방법
![[빅분기] PART4. 빅데이터 결과 해석 - 분석결과 해석 및 활용 - 분석결과 활용 (출제빈도 : 하)](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEj2tCMzQ5D2rhqkDfbphh9LKohFnYl3Df8LahM8gskD0BNHA5jX1MLhVIuG78S5IdyrrQrB60ygONq5FvYBLzrUnJrOhKpTfTFzZP0TFS_lZDipN44DhIq8FfFfnieRwTSzDCXvKacFQWvlcETOaoxXS0KNSFdN3apRHi5ReqUer7jCvbIFp2tj8Gmqci3S/w680/%EB%B9%85%EB%8D%B0%EC%9D%B4%ED%84%B0%20%EA%B5%AC%EC%B6%95%EB%B0%A9%EB%B2%95%EB%A1%A0%20%EB%B9%84%EA%B5%90.png)
0 댓글