
Recurrent Neural Network(RNN)

[RNN Architecture. 지금까지 본 구조와는 사뭇 다른데,
이번 시간이 지나고 나면 위 구조가 어떤 의미를 갖는지 알 수 있다.]
Sequential data는 말 그대로 연속적인 데이터인데, Variable 관점에서 본다면 각 변수 (X1, ... , Xt) 가 서로 dependent하다고 할 수 있다. 예를 들어 "I am a bo"까지가 입력변수로 주어졌다면 "y"를 예측함으로써 "I am a boy"를 완성시는 경우인데, 이런 연속된 변수들 간 dependency를 어떻게 modeling 하느냐가 바로 RNN의 핵심이다.
확률의 관점에서 본다면 지금까지 우리는 독립변수 X가 주어졌을 때 y일 확률 P(y | X) 을 계산해서 높은 확률을 갖는 y를 예측했다.
반면 RNN에서는 연속적인 X1, ... , Xt가 주어진 후 t시간에서 y일 확률 P(y | X1, X2, ... Xt)를 구하는 문제라고 할 수 있다.
RNN으로 풀 수 있는 Sequential data의 대표적인 예는 음악, 동영상, 자연어, 주가와 같다. 잘 생각해보면 자연어는 단어들의 sequence, 음악은 음계의 sequence, 동영상은 이미지의 sequence이며 previous value가 current value에 영향을 미치는(dependent) 것을 알 수 있다.
CNN을 활용해 할 수 있는 대표적인 사례는 아래와 같다.
- Speech recognition : 연속적인 음성을 text로 변형하는 것 (many-to-many)
- Machine translation : 언어 번역 (many-to-many)
- Sentiment analysis : text를 이해하고 긍정/부정을 판단하는 것 (many-to-one)
- Music generation : 음악을 이해하고 창작하는 것 (one-to-many)
- Video classification : 영상을 보고 어떤 종류의 영상인지 파악하는 것 (many to one)
위 사례를 설명하면서 many-to-many와 같이 표현한 것은 위 문제를 풀기 위한 RNN 구조의 형태를 의미하는데, 본 포스팅에서는 RNN의 기본 구조와 학습방법, RNN 구조를 잘 설계해서 좋은 성과를 낸 특별한 RNN 형태들에 대해서 알아본다.
RNN Architecture

우리가 지금까지 공부한 Feedforward Net을 간단히 표현하면 위 그림과 같다. input x를 W(weight), b(bias)로 parameterized 시킨 후 Activation function φ을 적용한 것이 hidden value가 되고, 마찬가지로 hidden value를 parameterized + Activate 시켜 output y를 예측하는 것이다.
1) Vanilla RNN
하지만 우리가 풀고자 하는 sequence 데이터는 time = 1~t-1 까지의 영향이 time = t까지 영향을 미치는 데이터이다. 그렇기 때문에 RNN은 아래와 같은 구조를 제안한다.


위 구조를 보면 h2는 x2만으로 y2를 예측하는 것이 아니라 x1의 영향을 받은 h1까지 반영하여 y2를 예측하는 것을 확인할 수 있다. 즉 state t의 예측을 위해 t-1 state의 영향을 반영하고, state t-1 의 영향을 파악하기 위해 state t-2을 살펴보아야 한다. 이렇게 재귀적(Recursive)인 구조를 갖는 네트워크가 RNN(Recurrent Neural Network) 기본(Vanilla RNN)이다.
※ Vanilla는 일종의 slag(한국말로 치면 사투리)이다. 바닐라(vanilla)맛 아이스크림에 딸기 시럽, 초코가루를 뿌리는 것처럼, 가장 base structure를 가진 모델을 vanilla model이라고 부른다.

참고로 위 그림을 우리가 익숙한 Full Network 시점으로 보면 위와 같다.
그럼 이제 Vanilla RNN 구조를 변형해 할 수 있는 일들에 대해 한번 살펴보자.
2) Many-to-Many
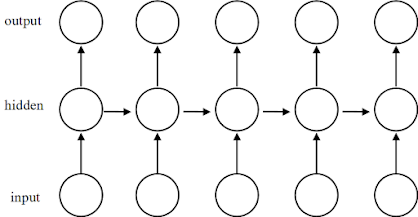
Many-to-Many는 Vanilla RNN구조와 유사한데, 위 그림과 같이 Vanilla RNN과 똑같은 구조를 가질 수도 있다. 위 상황을 「동기화된 시퀀스 입력 & 출력 」를 갖는다고 말하는데, 지금까지 나온 문장을 보고 다음에 나올 단어를 즉각적으로 예측하는 것을 예로 들 수 있다.
※ 'M' → 'y', 'My' → ' ', 'My ' → 'n', ... , 'My name is' 와 같이 즉각적으로 다음 글자를 예측하는 경우다. 어떤 글자가 올지는 학습된 데이터에 영향을 받는다. 지하철 방송 음성을 학습했다면 'My...'를 예측 하는 것이 아니라 'Metro..' 가 예측되었을 수도 있다.

※ 우리가 'I' → '나' 이렇게 즉각적으로 번역하는 것이 아니라 'I', 'am' 이 입력되고 나서야 'I' = '나'를 의미한다는 것을 알아채는 원리와 같다.
※ Input을 어떤 형태(Context vector)로 변환했다가(encoding), Output 으로 복원(decoding)한다고 해서 Encoder-Decoder 구조라고도 한다.
3) Many-to-One

자연어를 예로 들면 'I am a happy'를 입력받고 이 문장이 긍정의 감정인지, 부정의 감정인지를 출력할 수 있다.
혹은 sequential image인 동영상을 입력받고 이 동영상이 사고상황인지, 일반상황인지 구분하는 모델을 만들 수 있다.
4) One-to-Many

이미지의 경우라면 사진을 보고 사진을 설명하는 문장(sequence)를 출력할 수 있다.
혹은 계이름을 1개 주고 음악(sequence)을 만들어 볼 수도 있고, 단어를 1개 주고 문장, 혹은 소설(sequence)를 만는 등 Generation 모델을 만들 수 있다.
※ Music Generation with RNN 사례 : https://www.youtube.com/watch?v=0VTI1BBLydE
5) Bidirectional RNN

"나는 _____를 뒤집어 쓰고 펑펑 울었다."
예를들어 위의 빈칸을 유추하는 문제를 풀기 위해서는 앞보다는 뒤의 '를 뒤집어 쓰고'가 훨씬 중요하게 다루어지는 것과 마찬가지다.
Back propagation in RNN

일단 Total loss는 sequence output의 모든 loss의 합으로 구하기 때문에 더 설명할 것이 없다. 하지만 gradient를 구하기 위한 back propagation은 조금 특이한 특징을 가진다.
RNN의 오차역전파(Back propagation)는 위 그림처럼 시간의 역순으로 진행된다. 예를 들어 h(t-1)의 gradient는 는 y(t-1)과 h(t) 모두에게서 영향을 받는다. 이 때 중요한 것은 h(t)에서 h(t-1)로 gradient가 전파될 때 W의 전치행렬이 곱해진다는 것이다. 왜 그런지 확인해보자.
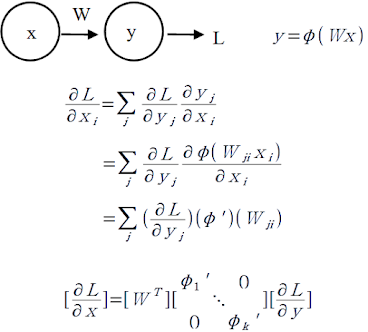

위에서 언급한 W의 전치행렬이 곱해지는 행위가 RNN에서는 반복되는데,
- W의 singular value(eigenvalue와 같다고 생각하면 된다.) 가 1보다 크다면 Exploding(발산) gradient,
- W의 singular value가 1보다 작다면 Vanishing(소멸) gradient
의 특징을 가지게 되는 문제점이 있다. 그리고 이런 문제를 해결하기 위해 LSTM, GRU 같은 Vanilla RNN을 개선한 RNN 구조가 제안되게 딘다.
Special RNN Architecture
1) LSTM (Long Short Term Memory)
Vanilla RNN의 문제점을 극복하기 위해서 1997년에 처음 발표됐다. 물론 이 때는 인공신명망의 낮은 관심 등으로 인해서 외면받았지만, 2000년대부터 폭발적인 관심을 받으며 지금까지도 RNN의주요 모델로 자리 잡고 있다.
※ S. Hochreiter and J. Schmidhuber(1997), "Long short-term memory." Neural Computation
Vanilla RNN의 문제점 중 하나는 ht는 ht-1의 정보를 주로 참고할 뿐 더 멀리 위치한 ht-3과 같은 영향은 크게 고려하지 않는다. 쉽게 예를 들면 "I am a b"의 다음글자 'o'를 예측할 때 'b'로 부터 온 영향만 고려하지 'a', 'm'에 대한 영향도는 매우 낮다. (앞서 설명했듯, W의 전치행렬이 계속 곱해지면서 gradient가 vanishing 되기 때문이다.)
LSTM은 이 문제를 해결하기 위해 최근 데이터(short term)와 한참 전 데이터(long term)를 함께 기억(memory)하면서 출력을 예측하는 모델이다.

앞서 Vanilla RNN의 h2는 x2뿐만 아니라 h1의 영향을 받는다는 것을 알 수 있었다.


위 그림의 LSTM도 ht를 구하기 위해 ht-1, xt가 Input gate와 Forget gate, Output gate에 sigmoid, tanh 함수를 거치며 0~1사이의 값으로 scaling 된 것을 알 수 있다. 물론 이 때 각각은 weight와 bias로 parameterized 되어 있다.

Cell은 일단 지금은 (+) 연산으로 생각하자.
![]()
Cell은 2개의 입력을 받는데, 첫 번째는 gt * it의 곱인 input gate의 출력이다. Cell의 두 번째 입력이 특이한데, Cell은 forget gate에게 Ct-1을 반환하고 ft와 Ct-1을 곱한값을 입력으로 돌려받는다.
위 식에서 forget gate의 역할이 눈에 보이기 시작하는데, 만약 ft가 0에 가깝다면 Ct-1의 영향은 거의 사라진다. 즉, 과거의 영향을 고려하지 않겠다는 것이다. 반대로 1에 가깝다면 과거의 영향이 상당히 의미를 가진단 뜻이 된다. 즉, ft은 일종의 forgetting factor라 볼 수 있다.
여튼, 이 때 현재 cell state Ct가 update되고 남은 것은 최종 출력 ht가 남았다.

 vs.
vs.
LSTM을 학습시키기 위한 gradient flow를 확인해보면,
vanilla RNN때와 같이 항상 같은 WT matrix multiplication이 발생하지 않고,
ft에 의한 element-wise multiplication만 존재하는 것을 확인할 수 있다.
즉, 예전 영향을 잘 반영하면서 gradient vanishing 문제점을 어느정도 해결한 모습이 확인된다.
※ 지금까지는 이해를 돕기 위한 그림이었고, 대중적으로는 아래와 같이 표현하는 것이 일반적이다.


[개발새발로그님의 블로그에 일반적인 표기법을 이용한 단계별 자세한 설명이 있다.]
2) GRU (Gated Recurrent Unit)
LSTM이 일반적인 sequential data를 위한 모델이라면 GRU는 자연어에 특화된 모델이라고 할 수 있다. 하지만 그 원리는 LSTM의 간소화 버전이라고 이해하면 쉽다.
※ K. Cho et al. (2014) : "Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation" EMNLP


위의 정의에서 볼 수 있듯, GRU는 forget gate를 위한 cell이 없고, ht-1을 더 많이 반영할건지 말건지를 결정하는 reset gate r만 존재한다.
Training RNNs for Sequence Prediction
Teacher Forcing


[without teacher forcing, 잘 예측한 경우]

[without teacher forcing, 잘 못 예측한 경우]
decoder의 장점이라 할 수 있는 특성은 학습에서는 치명적인 오류를 일으킬 수 있다.
decoder로 인해 예측된 문장은 우리가 의도하지 않은 문장일수도 있고, 이 뜻은 잘못된 문장이 학습될 수 있다는 것이다. 실제로 이런 현상은 초기 학습 속도의 저하, 모델의 성능 하락이라는 문제점을 가져온다. 이 때 사용되는 학습기법이 바로 Teacher Forcing이다.
※ 이미 모델이 어느정도 학습되어 있다면 올바른 예측 결과를 학습하기 때문에 문제가 없다. 학습 초기 모델은 위와 같이 전혀 다른 예측을 낼 수 있고, 그 결과를 학습하면 전혀 엉뚱한 방향으로 학습될 수 있다.

[with teacher forcing]
Scheduled Sampling
그런데 이렇게 했을 때 또 문제점이 있다. 그 이유는 test 할 때는 결국 예측값이 input으로 들어가 줘야 하기 때문이다.
Teacher forcing은 말 그대로 선생님이 옆에 있어서 계속 답이 맞는지 틀린지를 가르쳐준 일종의 Full supervised learning 방법이다. 하지만 실전 연습은 한번도 못해본 것이나 마찬가지기 때문에 학습이 어느 정도 됐을 때는 서서히 Teacher forcing을 줄여나가는 것이 효과적이다. 그 방법이 바로 Scheduled sampling이다.
※ 참고로 현재 대부분의 RNN 모델을 학습할 때는 Scheduled sampling을 적용하고 있다.

이 때 (1-ε)으로 동전던지기의 확률을 결정하는데, ε=1 이면 ground truth를 쓰겠단 의미다. 결국 ε이 처음에는 1이었다가 점점 0으로 줄어들면서 예측값을 사용할 수 있게끔 해 줘야하고, 이 과정을 decay schedule이라고 한다.
※ decay schedule은 linear decay / exponential decay / inverse sigmoid decay 등이 있다.
![[빅분기] PART4. 빅데이터 결과 해석 - 분석결과 해석 및 활용 - 분석결과 활용 (출제빈도 : 하)](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEj2tCMzQ5D2rhqkDfbphh9LKohFnYl3Df8LahM8gskD0BNHA5jX1MLhVIuG78S5IdyrrQrB60ygONq5FvYBLzrUnJrOhKpTfTFzZP0TFS_lZDipN44DhIq8FfFfnieRwTSzDCXvKacFQWvlcETOaoxXS0KNSFdN3apRHi5ReqUer7jCvbIFp2tj8Gmqci3S/w680/%EB%B9%85%EB%8D%B0%EC%9D%B4%ED%84%B0%20%EA%B5%AC%EC%B6%95%EB%B0%A9%EB%B2%95%EB%A1%A0%20%EB%B9%84%EA%B5%90.png)
){kind=link}
2 댓글
첫문단 이부분에서
답글삭제을 활용해 할 수 있는 대표적인 사례는 아래와 같다.
Speech recognition : 연속적인 음성을 text로 변형하는 것 (many-to-many)
Machine translation : 언어 번역 (many-to-many)
.....
CNN -> RNN으로 수정되어야 할 것 같습니다!
앗.. 감사합니다. 오타가 났네요 ㅠㅠ ;
삭제