
Multi-armed Bandits
추후에 배울 Markov Decision Process를 배우기 위한 전초단계로 집중하도록 하자.
Multi Armed Bandit Problem

강화 학습(RL : Reinforcement Learning)의 가장 큰 특징은 정답 혹은 라벨을 주는 것이 아니라 행동에 대한 평가(evaluate)만 한다는 것이다. 그럼 모델은 평가를 피드백 받고(evaluative feedback) 시행착오를 겪으면서 학습된다.
- Supervised Learning : Instructive feedback
- 정답을 명확하게 가르쳐 주는 방식으로 학습하는 방법이다.
- Reinforcement Learning : Purely evaluative feedback
- Action이 얼마나 좋은지/나쁜지에 대한 판단만 제공한다.
MAB(Multi-armed Bandit) 문제는 가장 심플한 RL의 toy example로써,
1개의 상황(state)만 있는 단순한(non-associative)한 특징을 가지고 있어서,
추후에 다룰 강화학습 문제로 확장해 적용할 수 있다.
※ non-associative : 행동(action)이 상황(state)에 영향을 미치지 않음.
MAB는 state가 1개 뿐이기 때문에 영향을 받을 state도 없다.
MAB 문제는 아래와 같이 정의 할 수 있다.
- k개의 기계를 1명이 k번 조작하며, 각 기계에서 얻을 수 있는 보상(reward)은 다르다.
- 이 때 i번째 기계를 조작한 행위(Action)를 Ai로 정의한다.
- 그리고 Ai를 통해 얻을 수 있는 보상(Reward)를 Ri로 정의한다.
- MAB 문제는 보상이 최대일 수 있는 행위를 찾는 문제이다.
(To maximize the expected total reward)
이번 챕터에서는 위와 같이 정의한 MAB 문제를 통해 RL의 가장 기본적인 원리를 알아보자.
Exploration vs. Exploitation

이미 입증된 음식점(exploitation)을 갈 때는 통상 실패할 일이 잘 없다.
하지만 새로 오픈한 새로운 식당에 대한 것은 일종의 '탐험(exploration)'이라고 할 수 있다. 물론 이 때 실패할 수 있다는 리스크는 있지만 전에 없던 새로운 맛을 찾을 수 있는 기대도 할 수 있다.

위에서 비유한 Exploitation과 Exploration은 RL에서도 굉장히 중요한 개념이다.
우리가 취할 수 있는 행위를 A라고 하자. 이 때 얻을 수 있는 보상 R을 Reward 혹은 Value 라고 한다.
그리고 RL은 Reward를 최대화 하는 목적을 가지는 모델이다.
- At : time=t 일 때 취한 Action
- Rt : Action을 통해 얻은 Reward
- a라는 Action을 취했을 때 얻을 수 있는 총 Reward 기대값(평균)
- 하지만 우리는 q*(a)를 알 수 없기 때문에 추정(estimate)해야한다.
- 우리는 Qt(a)를 q*(a)에 가깝게 추정해야 최적의 Action을 결정(Policy)할 수 있다.
Policy를 정하는 가장쉬운 대표적인 방법은 Greedy action이다.
※ Policy : 어떤 Action을 취할지 결정하는 방법

만약 위와 같이 time=t일때 취할 수 있는 action이 a1, a2, a3가 있고, time=t+1일때도 마찬가지라고 가정하다.
이 때 예상되는 Reward의 추정값 Q(a)들이 계산 되는 경우, Reward가 가장 큰 action을 취하는 Policy가 Greedy action이다.
- 이 때, greedy action만 취한다면, 예상 가능한 범주내에서 선택하는 것을 의미함으로 Exploiting이라고 할 수 있다. (~ 입증된 음식점)
- 반면, 종종 non-greedy action을 취한다면 예상을 넘어서는 Reward를 취할 수도 있고 반대로 실패할 수도 있다. 이 경우를 Exploring이라 할 수 있다. (~ 새로 오픈한 음식점)
당연히 한쪽에 편향되지 않고 이 두가지 경우를 적절히 balancing 했을 때 좋은 효과를 얻을 수 있을 것은 자명하다.
Action-value methods
어쨋든 policy를 정하려면, 일단 가장 먼저 해야할 것은 action에 대한 value(=reward)를 먼저 estimate할 수 있어야 한다. (→ 앞서 언급한 Q(a))
그리고 MAB 문제에서의 expected value는 아래와 같이 심플하게 정의된다.
[Average the rewards actually received]

즉, t시점에서 action a를 취했을 때 expected value Q는
t시점 이전에 a을 취했을 때 받은 reward의 평균으로 정의된다.
여기서 몇 가지 더 고려해야되는 점이 있다.
- 만약 a가 bandit을 당기는 행위일때, bandit을 전혀 당기지 않았다면 분모가 0이 된다. 이 때는 예외로 Q(a) = 0으로 둔다.
- 무한하게 action을 취한 경우(t→∞) 큰 수의 법칙에 의해서 Q(a) = q*(a) 로 수렴한다.
앞서 배운 Greedy action selection method를 위에서 정의한 Qt(a)를 이용해 표현하면 아래와 같다.
즉, 가장 큰 추정값 Q를 도출하는 a가 greedy action이다.
이 때 항상 Greedy action만 취한 경우를 greedy method policy라 할 수 있는데,
가끔은 확률적으로 non-greedy action을 갖게할 수도 있다. (ε-greedy method)
- 1-ε의 확률로 greedy action을 고르고 (exploitation, 가장 좋은 arm을 당긴다)
- ε 확률로 non-greedy action을 고른다. (exploration, random한 arm을 당긴다)

실제로 k=10인 MAB 문제를 ε-greedy로 풀어본 결과이다.
위 그래프는, value(=reward)를 discrete한 평균값 q*로만 판단하는 것이 아니라,
σ=1의 분산을 갖는 분포로 가정하여 때로는 non-greedy action을 고를 수 있게 한 것을 보여준다.

이 실험은 인해 RL에서 Exploitation & Exploration의 적절한 balance가 중요하다는 것을 보여준 Toy example이라고 할 수 있다.
Incremental update rule
expected value와 policy를 결정했다면 이제 실제로 구현(Implement)할 차례이다.
그리고 무엇보다 가장 핵심은 역시 앞서 배운 action value method 를 구현하는 것이다.
그리고 action value method 의 시작은 expected value Q를 구하는 것이고, Qt는 t-1까지의 observed value로 부터 구해진다는 것을 조금 전에 배웠다.
즉, 우리가 implementation을 위해 할 가장 첫번째는 Qn(expected reward)을 과거 값 Ri(, observed reward)들로 부터 incremental하게 구할 수 있는 점화식을 정의한 후 프로그래밍 하는 것이다. 이 때 expected reward는 아래와 같다. (sample average)

참고로 이 때 1, ... , n-1은 1개 기계를 1번 당겼을 때, n-1번 당겼을 때 관측된 Reward라고 이해해야 한다. Qn은 기계의 갯수만큼 구해진다. (앞서 k=1 MAB 그래프를 떠올려 보자.)

앞서 정의한 점화식을 전개, 분해 등을 하다 보면 위와 같이 n번째 관측됐던 reward와 추정한 reward의 항으로 표현할 수 있다. n=1부터 대입하며 몇가지 테스트 해보자.

- 일단 가장 작은 단위인 Q2는 R1으로 정의 되기 때문에 Q1, R1은 초기값으로 주어져야 한다.
- StepSize역할을 하는 1/n이 stationary하다.
(ex. Q4에 대한 R1, R2, R3 비중이 1/3으로 동일하다.)
Tracking non-stationary problem
하지만 sample average는 변하지 않는 환경(stationary) 에서나 잘 동작한다.
(n번째 사건의 비중 → n-1번째의 비중 = n-2번째의 비중... 으로 동일(stationary))
하지만, 대부분의 경우 아주 먼 과거의 결과보다 가까운 과거의 결과가 훨씬 큰 영향을 미친다. 즉, 우리는 MAB 문제를 non-stationary problem으로 바라볼 필요가 있다.
동일한 점화식을 사용하되 1/n으로 고정된 step size를 α ∈[0, 1]를 가지는 파라미터로 전환하면 아래와 같이 변환할 수 있다.

그리고 마찬가지로 R1, Q1은 초기값으로 주어져야 하는 것이 목격되고 있다.
Optimistic initial values
앞서 MAB 문제를 non-stationary 문제로 모델링 했는데, 모델링한 사람이 직접 제시해야 하는 값들이 있다. (=하이퍼파라미터)
바로 non-greedy policy를 선택할 확률 ε, 지난 사건들의 weight을 결정하는 α와 initial action value estimate Q1이다.
이 중 ε과 α의 효과에 대해서는 앞에서 살펴봤으니 이번에는 초기값에 대해서 알아보자.
![]()
즉, Q1이 클 수록 Qn을 추정하는데 영향을 미친다고 할 수 있으며, Q1을 잘 추정하는 것도 중요하고 할 수 있다. (→ 하이퍼파라미터)
기존에는 Q를 N(q*, 1)의 분포에서 샘플링할텐데, q* 주변값을 선택할 가능성이 높을 것이다.
그런데 만약 Q1 값을 기존값보다 더 크게 셋팅한다고 가정해보자.
그럼 분명 q* 주변이긴 하겠지만 좀 더 큰 기대값을 선택할 가능성이 더욱 높아진다.
즉, initial value를 증가시키면 action value method가 exploring할 경향을 높혀준다.

위 그래프는 10-armed bandit 문제의 초기값 Q1을 다르게 했을 때 결과이며, 초기값에 따라 optimal action을 선택했을 확률이 높아지는 것을 확인할 수 있다.
즉, policy가 exploring 하기 위해서는 ε-greedy method의 ε, 그리고 Q(a)를 구하기 위한 initial value가 하이퍼파라미터로 동작한다는 것을 알아보았다.
Gradient bandit algorithms
지금까지는 value-based 기반으로 action을 선택했다. 이번에는 policy-based 기반으로 action을 선택해보자.
먼저 value-based 기반으로 action을 선택할 때의 문제점을 알아보자.

a1, a2, a3, a4에 대한 expected value가 위와 같이 계산되었다고 가정하자.
ε-greedy method는 (1 - ε)의 확률로 exploitation, 나머지 확률로 exploration하는 알고리즘이기 때문에, 위와 같이 policy π(a)가 정의된다.
그런데 상당히 납득되지 않는 부분이 있다. a3에 대한 기대값은 a2에 대한 기대값과 큰 차이가 나지 않음에도 불구하고, ε/4의 확률로 선택된다. 상식적으로 기대값이 높을 수록 선택될 확률이 높은 policy가 합리적이라고 생각되는데, 이 때 등장한는 것이 '선호도(preference)' 개념이며, 이를 구현한 알고리즘이 Gradient Bandit Algorithm이다.


위 식이 바로 선호도(preference)를 gradient ascent 방식으로 구하는 식이며,
expected reward E를 최대화 되도록 선호도 H가 update되는 것을 확인할 수 있다.
※ 위 식이 익숙치 않다면 Gradient decent에 관련된 포스팅을 확인하도록 하자.
하지만 위 식에 있는 q*(x)를 모르기 때문에 우리는 이 식을 directly implement하기가 어렵다.
그럼 미분항만 따로 떼서 implement 하기 쉽게 변형시켜보자.

먼저 expected reward의 정의를 대입했을 때, true value인 q*(x)는 action의 함수인 H(a)와는 상관없는 상수이기 때문에 미분항에서 꺼낼 수 있다.
그리고 아무 의미없는 x와 무관한 상수 Bt를 사용해서 위와 같이 표현하자.
(어차피 gradient=0 인 지점을 찾는 문제이기 때문에 상수항이 하나 붙어도 상관없다.)
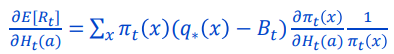
그리고 π(x)를 곱하고 나눠서 소거될 수 있게 추가해주자.
이렇게 하는 이유는 gradient를 expectation 형태로 표현하기 위함이다.

q*의 expectation은 R로 관측되는 값이고, B는 아무 값이나 넣어도 상관없으니 R_(bar)로 바꿔서 표현했다. (추후에 R과 비교하기 위한 baseline으로 사용한다.)
그리고 π를 H로 편미분한 것은 저렇게 구할 수 있다고 한다. (너무 깊게 알려고 하지 말자..)

그럼 최종적으로 위와 같이 미분항을 정리할 수 있고,
![]()
이걸 좀 직관적으로 표현하면 아래와 같이 표현할 수 있다.

여기서 R_(bar)는 R과 비교하기 위한 baseline이라 한다. (baseline보다 높다면 현재 action의 우선순위가 높아진다.)
Summary
- action a에 대한 value의 정의는 아래와 같다.
- 하지만 q*는 관측되지 않는한 구할 수 없음으로 아래와 같이 근사화 한다.
1) stationary problem2) non-stationary problem

- policy : action을 선택하기 위한 rule
(value가 높은 것을 선택하는 것 = greedy method)
- ε-greedy method : policy를 선택할 때 exploration과 exploitation의 balance를 맞춰주는 간단한 방법
- exploration을 encourage하는 또 다른 방법으로는 optimistic initial value를 찾는 방법이 있다.
- Gradient bandit algorithm : action value Q를 estimate하는 대신 action preference H 를 사용하는 방법이며, H는 gradient ascent로 학습된다. 더 preferred된 action에 대해 favor를 주기 위해 softmax 분포를 사용한다.
![[빅분기] PART4. 빅데이터 결과 해석 - 분석결과 해석 및 활용 - 분석결과 활용 (출제빈도 : 하)](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEj2tCMzQ5D2rhqkDfbphh9LKohFnYl3Df8LahM8gskD0BNHA5jX1MLhVIuG78S5IdyrrQrB60ygONq5FvYBLzrUnJrOhKpTfTFzZP0TFS_lZDipN44DhIq8FfFfnieRwTSzDCXvKacFQWvlcETOaoxXS0KNSFdN3apRHi5ReqUer7jCvbIFp2tj8Gmqci3S/w680/%EB%B9%85%EB%8D%B0%EC%9D%B4%ED%84%B0%20%EA%B5%AC%EC%B6%95%EB%B0%A9%EB%B2%95%EB%A1%A0%20%EB%B9%84%EA%B5%90.png)
{kind=link}
0 댓글